
This post is for folks with some background in cryptography. It surveys the expanding crypto-verse of proof systems and the role of symmetric STARKs within. Based on a talk delivered in San Francisco in November 2019.
1. Introduction
For 3.5 billion years, life on earth consisted of a primordial soup of single-cell creatures. Then, within a geological eyeblink, during what is known as the Cambrian Explosion, nearly all animal phyla we recognize today emerged.
By analogy, we are currently experiencing a Cambrian Explosion in the field of cryptographic proofs of computational integrity (CI), a subset of which include zero knowledge proofs. While a couple of years ago there were about 1–3 new systems a year, the rate has picked up so much that today we are seeing this same amount monthly, if not weekly. To wit, in 2019 we’ve learned of new constructions like Libra, Sonic, SuperSonic, PLONK, SLONK, Halo, Marlin, Fractal, Spartan, Succinct Aurora, and implementations like OpenZKP, Hodor, and GenSTARK. Oh, and as the ink is drying on this post, RedShift and AirAssembly come along.
How to make sense of all this marvelous innovation? The purpose of this post is to identify the common denominators of all CI systems implemented in code and discuss a few differentiating factors.
Please note that this article will be a bit technical, as it assumes some cryptography background! This may nevertheless be worth skimming for the interested non-cryptographer to get a sense of the lingo used in the field. With that said, our descriptions will be brief, and intentionally imprecise from a mathematical viewpoint. Another major goal of this post is to explain why our company StarkWare is placing all its chips in terms of science, engineering and products on a specific subfamily of the CI-verse, called henceforth symmetric STARKs.
Common Ancestors
Computational integrity proof systems can help solve two fundamental problems that afflict decentralized blockchains: privacy and scalability. Zero Knowledge Proofs (ZKPs¹) provide privacy by shielding some inputs of a computation without compromising integrity. Succinctly verifiable CI systems deliver scalability by exponentially compressing the amount of computation needed to verify the integrity of a large batch of transactions.
All CI systems that have been realized in code share two commonalities: all use something called arithmetization, and all cryptographically enforce a concept called “low-degree compliance” (LDC)².
Arithmetization is the reduction of computational statements made by a proving algorithm. You might start from a conceptual statement like this:
“I know the keys that allow me to spend a shielded Zcash transaction”
And translate it into an algebraic statements involving a set of bounded-degree polynomials, like:
“I know four polynomials A(X), B(X), C(X), D(X), each of degree less than 1,000, such that this equality holds: A(X)*B²(X)-C(X) = (X¹⁰⁰⁰–1)*D(X)”
Low-degree compliance means using cryptography to ensure that the prover actually picks low-degree polynomials³ and evaluates those polynomials on randomly chosen points requested by the verifier. In the example above (that we’ll keep referring to in this post), a good LDC solution assures us that when the prover is asked about x₀, it will answer with the values a₀, b₀, c₀, d₀ that are the correct values of A, B, C and D on input x₀. The tricky part is that a prover might pick A,B,C and D after seeing the query x₀, or may decide to answer with arbitrary a₀, b₀, c₀, d₀ that appease the verifier and do not correspond to any evaluation of pre-chosen low-degree polynomials. So, all that cryptography goes to prevent such attack vectors. (The trivial solution that requires the prover to send the complete A,B,C, and D delivers neither scalability, nor privacy.)
With this in mind, the CI-verse can be mapped out according to (i) the cryptographic primitives used to enforce LDC, (ii) the particular LDC solutions built with those primitives and (iii) the kind of arithmetization allowed by these choices.
2. Dimensions of Comparison
I. Cryptographic Assumptions
From 30,000 feet, the biggest theoretical distinguishing factor among different CI systems is whether their security requires symmetric primitives or asymmetric ones (see Figure 1). Typical symmetric primitives are SHA2, Keccak (SHA3), or Blake, and we assume they are collision resistant hash (CRH) functions, pseudorandom and behave like a random oracle. Asymmetric assumptions include things like hardness of solving the discrete logarithm problem modulo a prime number, an RSA modulus, or in an elliptic curve group, hardness of computing the size of the multiplicative group of an RSA ring, and more exotic variants of such problems, like the “knowledge of exponent” assumption, the “adaptive root” assumption, etc.
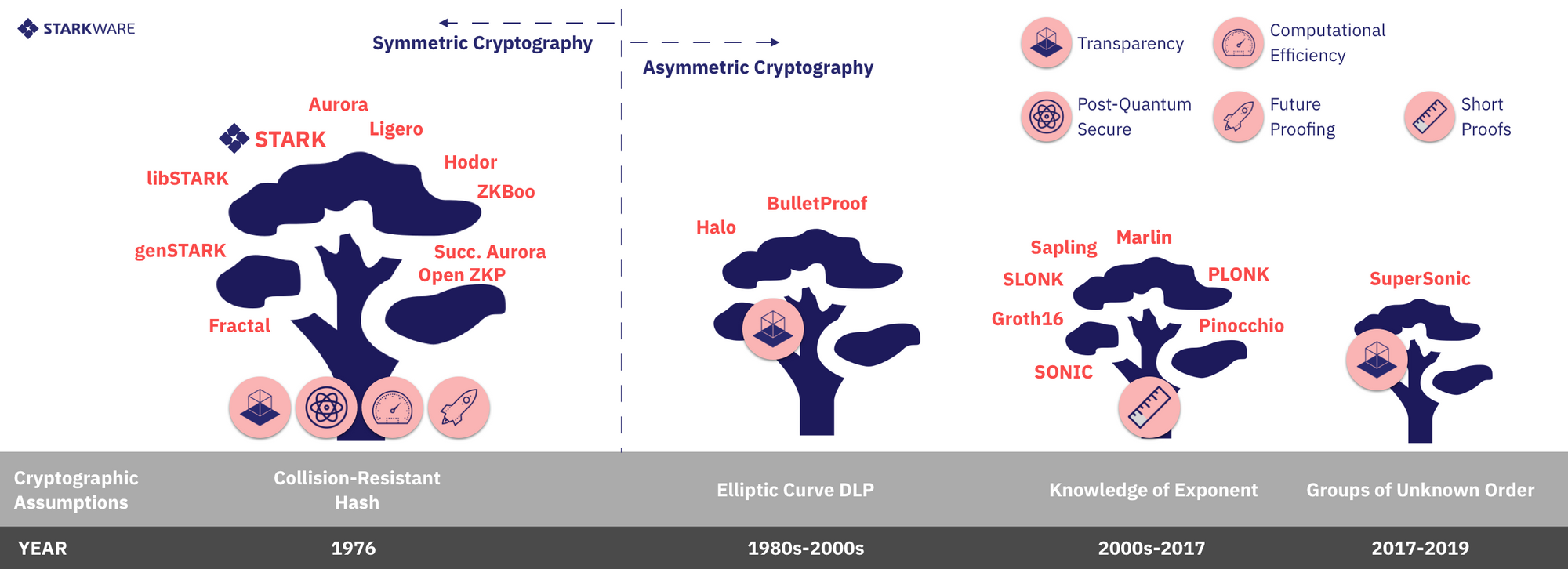
This symmetry/asymmetry divide between CI systems has many consequences, among them:
A. Computational Efficiency
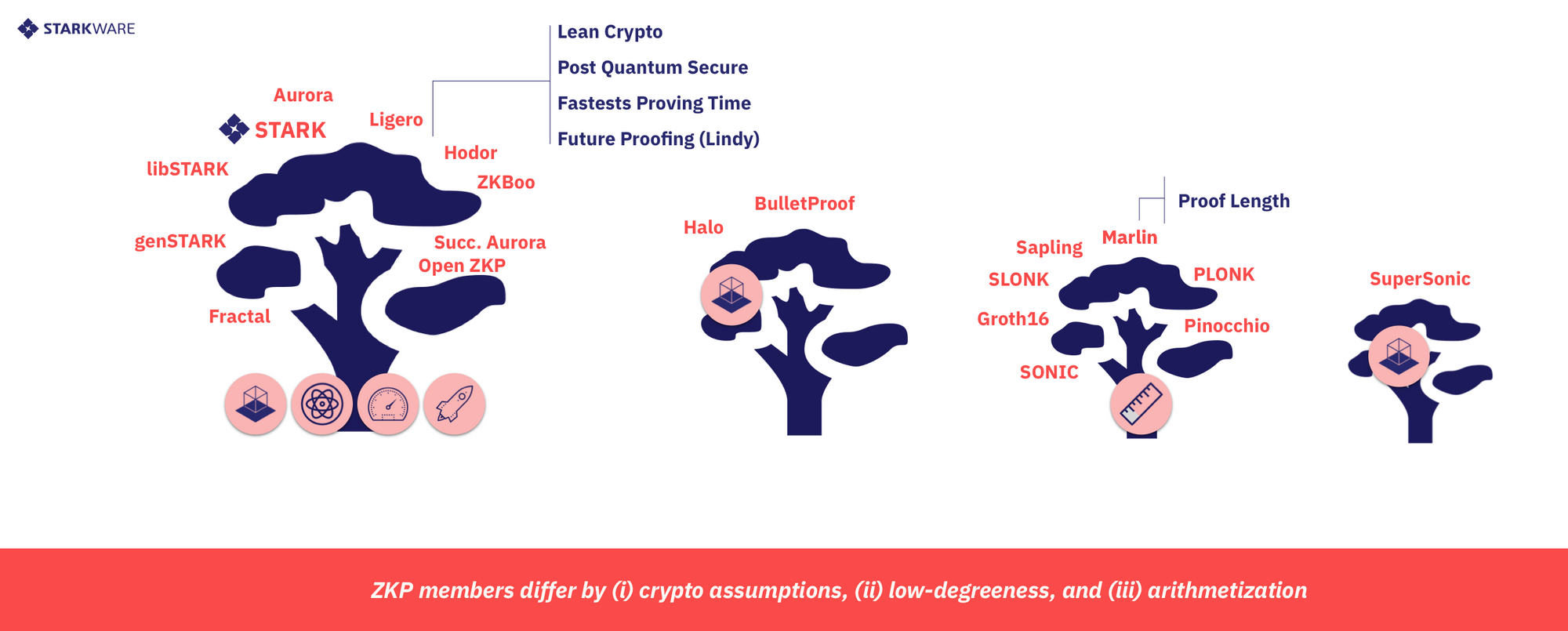
The security of asymmetric primitives implemented today in code⁴ requires one to arithmetize and solve LDC problems over large algebraic domains: large prime fields and large elliptic curves over them, in which each field/group element is hundreds of bits long, or integer rings in which each element is thousands of bits long. By contrast, constructions relying only on symmetric assumptions arithmetize and perform LDC over any algebraic domain (ring or finite field) that contains smooth⁵ sub-groups, including very small binary fields and 2-smooth prime fields (64 bits or less), in which arithmetic operations are fast.
Takeaway: symmetric CI systems can arithmetize over any field, leading to greater efficiency.
B. Post-Quantum Security
All asymmetric primitives currently used in the CI-verse will be broken efficiently by a quantum computer with sufficiently large state (measured in qubits), if and when such a computer appears. Symmetric primitives, on the other hand, are plausibly post-quantum secure (perhaps with larger seeds and states per bit of security).
Takeaway: Only symmetric systems are plausibly post-quantum secure.
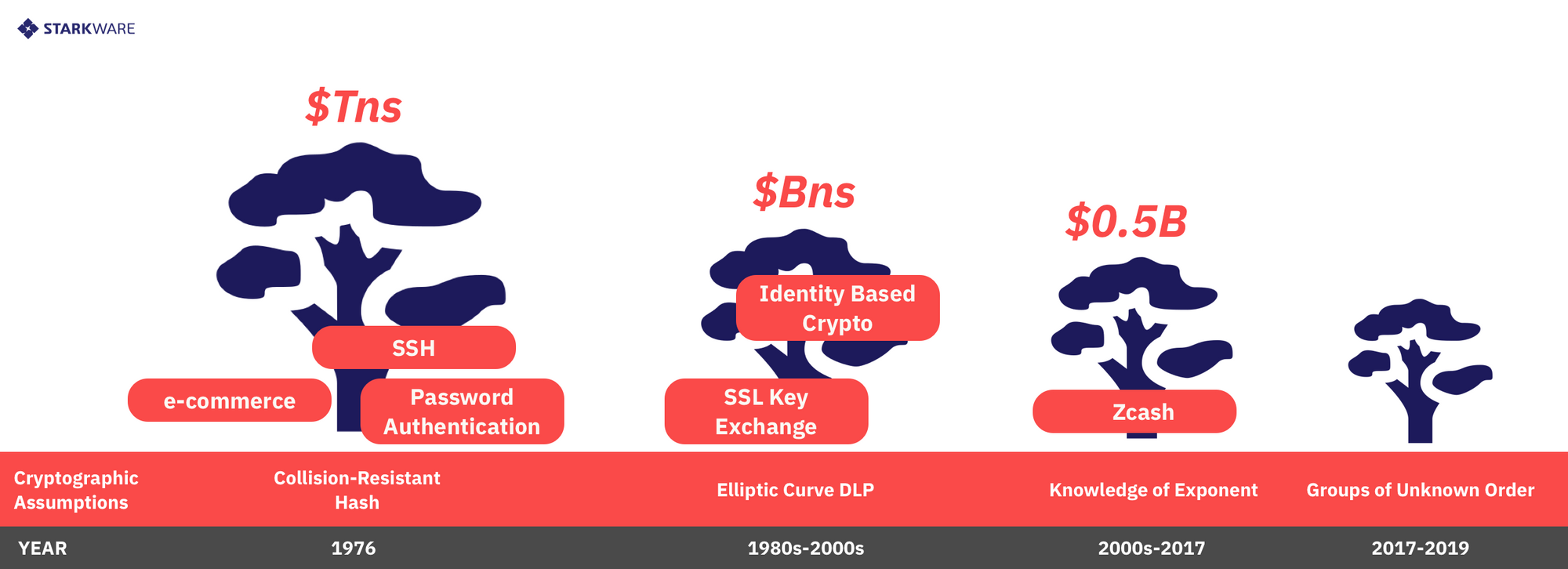
C. Future-Proofing
The Lindy Effect theory says that “the future life expectancy of some non-perishable things like a technology or an idea is proportional to their current age.” or in plain English, old stuff survives longer than new stuff. In the area of cryptography, this can be translated as saying that systems which rely on older, battle-tested primitives are safer and more future-proof than newer assumptions whose tires have been kicked less (See Figure 2). From this angle, new variants of asymmetric assumptions like groups of unknown order, the generic group model and knowledge of exponent assumptions are younger and have pulled a lighter economic cart than older assumptions like the more standard DLP and RSA assumptions that are used, e.g., for digital signatures, identity based encryption and for SSH initialization. These assumptions are less future-proof than symmetric assumptions like the existence of a collision resistant hash because these latter assumptions (and even specific hash functions) are the brick and mortar used to secure computers, networks, the Internet and e-commerce.
Moreover, there’s a strict mathematical hierarchy among these assumptions. The CRH assumption reigns in this hierarchy because if this assumption is broken (meaning that no safe cryptographic hash function is to be found) then, in particular, the RSA and DLP assumptions are also broken because those assumptions imply the existence of a good CRH! Similarly, the DLP assumption reigns over the knowledge of exponent (KoE) assumption because if the former (DLP) assumption fails to hold, then the latter (KoE) also fails to hold. Likewise, the RSA assumptions reigns over the group of unknown order (GoUO) assumption because if RSA is broken then GoUO also breaks.
Takeaway: New asymmetric assumptions are a riskier foundation for financial infrastructure.
D. Argument Length
All points made above favor symmetric CI constructions over asymmetric ones. But there’s one area in which asymmetric constructions fare better. The communication complexity (or argument length) associated with them is smaller by 1–3 orders of magnitude (Nielsen’s Law⁶ notwithstanding). Famously, the Groth16 SNARK is shorter than 200 bytes at an estimated level of 128-bits of security, whereas all symmetric constructions existing today require dozens of kilobytes for the same security level. It should be noted that not all asymmetric constructions are as succinct as 200 bytes. Recent constructions improve on Groth16 by (i) removing the need for a trusted setup (transparency) and/or (ii) handling general circuits (Groth16 requires one trusted setup per circuit). But these newer constructions have arguments that are longer, reaching sizes between a half a kilobyte (as is the case of PLONK) to a double-digit number of kilobytes, nearing the argument length of symmetric constructions.
Takeaway: asymmetric circuit-specific systems (Groth16) are shortest, shorter than all asymmetric universal ones, and all symmetric systems.
To reiterate the above takeaways:
- Symmetric CI systems can arithmetize over any field, leading to greater efficiency
- Only symmetric systems are plausibly post-quantum secure
- New asymmetric assumptions are a riskier foundation for financial infrastructure
- Asymmetric circuit-specific systems (Groth16) are shortest, shorter than all asymmetric universal ones, and all symmetric systems
II. Low Degree Compliance (LDC) Schemes
There are two main ways to achieve low degree compliance: (i) hiding queries and (ii) commitment schemes (see Figure 3). Let’s go over the differences.
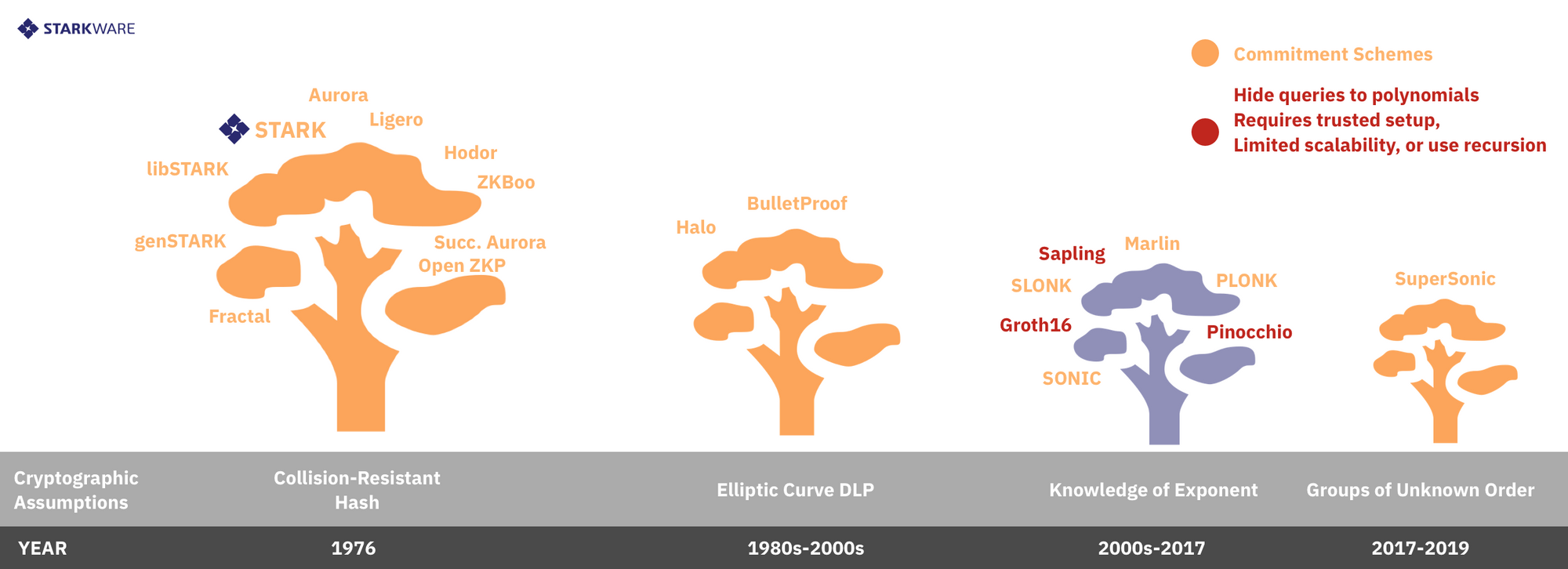
Hiding Queries
This approach (formalized here) is the one used by the Zcash-style SNARKs like Pinocchio, libSNARK, Groth16, and systems built on them like Zcash's Sapling, Ethereum's Zokrates, etc. To get the prover to answer correctly, we use homomorphic encryption to hide, or encrypt, x₀ and supply enough information so that the prover can evaluate A, B, C and D on x₀ . Actually, what is given to the prover is a sequence of encryptions of powers of x₀ (i.e., encryptions of x₀¹ , x₀², … x₀¹⁰⁰⁰) so that the prover can evaluate any degree-1000 polynomial, but only polynomials of degree at most 1,000. Roughly speaking, the system is secure since the prover does not know what x₀ is, and this x₀ is randomly (pre-)selected, so that if the prover tries to cheat then with very high probability they will be exposed. A trusted pre-processing setup phase is needed here to sample x₀ and encrypt the sequence of powers above (and additional information), leading to a proving key that is at least as large as the circuit of the computation being proved (there's also a verification key which is much shorter). Once the setup has been completed and the keys released, each proof is a single, succinct, noninteractive argument of knowledge (or SNARK, for short). Notice that this system does require some form of interaction, in the form of the pre-processing phase, which is unavoidable for theoretical reasons. Notice also that the system is not transparent, meaning that the entropy used to sample and encrypt x₀ cannot be simply public random coins, because any party that knows x₀ can break the system and prove falsities. Generating an encryption of x₀ and its powers without revealing x₀ is therefore a security issue that constitutes a potential single point of failure.
Commitment Schemes
This approach requires the prover to commit to the set of low-degree polynomials (A,B,C and D, in the example above) by sending some cryptographically crafted commitment message to the verifier. With this commitment in hand, the verifier now samples and queries the prover about a randomly chosen x₀, and now the prover replies with a₀, b₀, c₀, and d₀ along with additional cryptographic information that convinces the verifier that the four values revealed by the prover comply with the earlier commitment sent to the verifier. Such schemes are naturally interactive and many of them are transparent (all messages generated by the verifier are simply public random coins). Transparency allows one to compress the protocol into a non-interactive one via the Fiat-Shamir heuristic (which treats a pseudorandom function like SHA 2/3 as a random oracle that provides "public" randomness), or to use other public sources of randomness like block-headers. The most prevalent transparent commitment scheme is via Merkle trees, and this method is plausibly post-quantum secure but leads to the large argument lengths seen in many symmetric systems (due to all the authentication paths that need to be revealed and accompany each prover answer). This is the method used by most STARKs like libSTARK and succinct Aurora, as well as by succinct proof systems like ZKBoo, Ligero, Aurora and Fractal (even though these systems do not satisfy the formal scalability definition of a STARK). In particular, the STARKs we're building at StarkWare (like the StarkDEX alpha and the StarkExchange we're deploying soon) fall under this category. One may use asymmetric primitives to construct commitment schemes, e.g., ones based on the hardness of the discrete log problem over elliptic curve groups (this is the approach taken by BulletProofs and Halo), and the groups of unknown order assumption (as done by DARK and SuperSonic). Using asymmetric commitment schemes comes with the pros and cons mentioned previously: shorter proofs but longer computation time, quantum susceptibility, newer (and less studied) assumptions and, in some cases, loss of transparency.
III. Arithmetization
The choice of cryptographic assumption and LDC methods also affect the range of arithmetization possibilities, in three noticeable ways (See Figure 4):
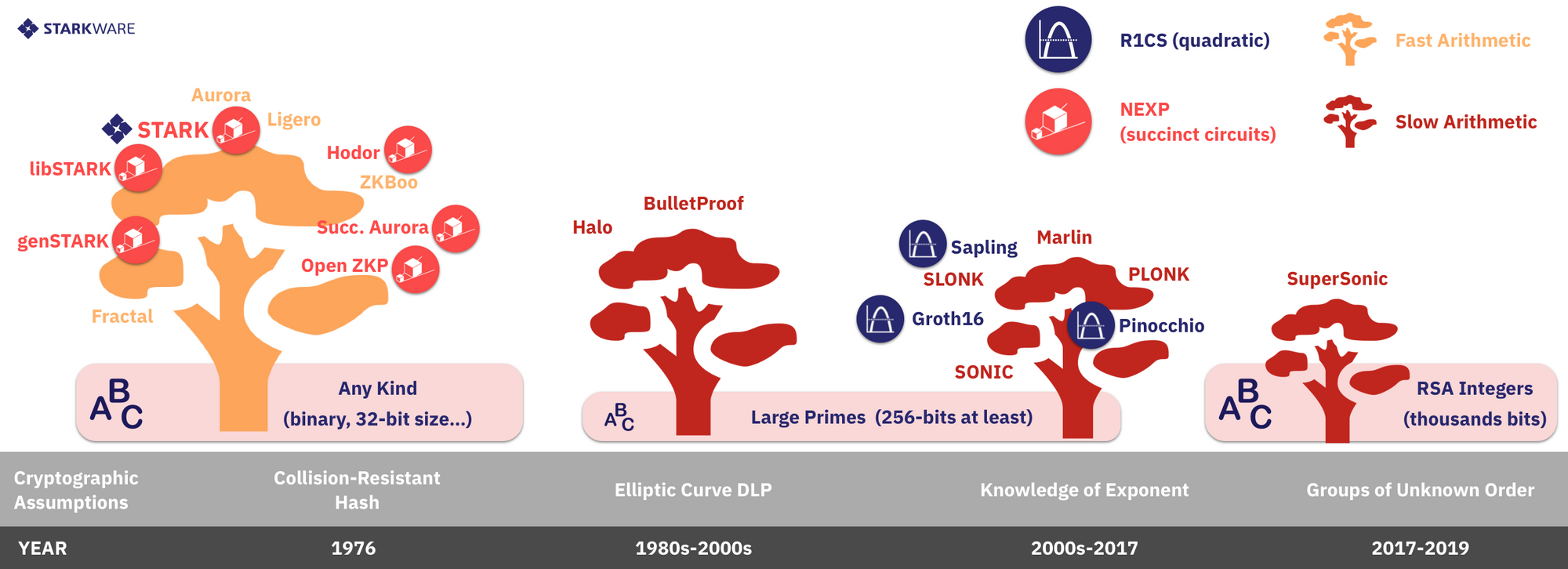
A. NP (circuits) vs. NEXP (programs)
Most implemented CI systems reduce computational problems to arithmetic circuits which are then converted to a set of constraints (typically, R1CS constraints, discussed below). This approach allows for circuit-specific optimizations but requires the verifier, or some entity trusted by it, to perform a computation that is as large as the computation (circuit) being verified. For multi-use circuits like Zcash's Sapling circuit, this arithmetization suffices. But systems that are scalable and transparent (no trusted setup) like libSTARK, succinct Aurora and the systems StarkWare is building, must use a succinct representation of computation, one that is akin to a general computer program and which has a description that is exponentially smaller than the computation being verified. The two existing methods for achieving this - (i) Algebraic Intermediate Representations (AIRs) used by libSTARK, genSTARK and StarkWare's systems, and (ii) succinct R1CS of succinct-Aurora, are best described as arithmetizations of general computer programs (as opposed to circuits). These succinct representations are powerful enough to capture the complexity class of nondeterministic exponential time (NEXP), which is exponentially more expressive and powerful than the class of nondeterministic polynomial time (NP) described by circuits.
B. Alphabet Size and Type
As pointed above, the cryptographic assumptions used also dictate to a large extent which algebraic domains can serve as the alphabet over which we arithmetize. For instance, if we use bilinear pairings, then the alphabet we'll use for arithmetization is a cyclic group of elliptic curve points, and this group must be of large prime size, meaning that we need to arithmetize over this field. To take another example, the SuperSonic system (in one of its versions) uses RSA integers and in this case the alphabet will be a large prime field. By contrast, when using Merkle trees the alphabet size can be arbitrary, allowing arithmetization over any finite domain. This includes the examples above but also arbitrary prime fields, extensions of small prime fields such as binary fields. The field type matters because smaller fields lead to faster proving and verification time.
C. R1CS vs. General Polynomial Constraints
Zcash-style SNARKs make use of bilinear pairings over elliptic curves to arithmetize the constraints of the computation. This particular use⁷ of bilinear pairings limits arithmetization to gates that are quadratic Rank-1 Constraint Systems (R1CS). The simplicity and ubiquity of R1CS has led many other systems to use this form of arithmetization for circuits, even though more general forms of constraints can be used, like arbitrary rank quadratic forms, or constraints of higher degree.
3. STARK vs. SNARK
This is a good opportunity to clarify the differences between STARKs and SNARKs. Both terms have concrete mathematical definitions, and certain constructions can be instantiated as STARKs, or SNARKs, or as both. The different terms put emphasis on different properties of proof systems. Let's examine these in more detail (see Figure 5).
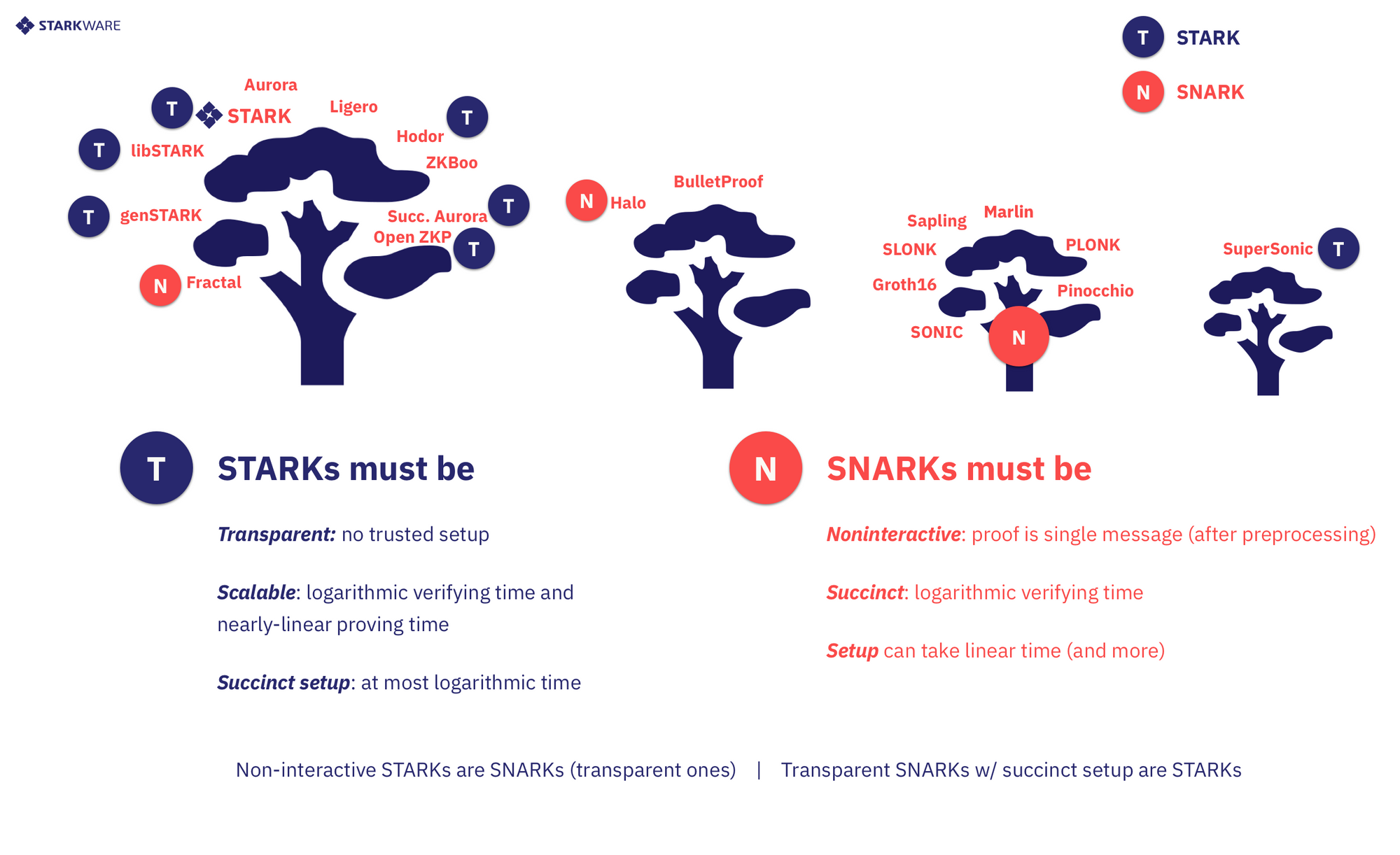
STARK
The S here stands for scalability, which means that as batch size n increases , proving time scales quasi-linearly in n and, simultaneously, verifying time scales poly-logarithmically⁸ in n. The T in STARK stands for transparency, which means all verifier messages are public random coins, (no trusted setup). According to this definition, if there’s any pre-processing setup, it must be succinct (poly-logarithmic) and must consist merely of sampling public random coins.
SNARK
The S here stands for succinctness, which means that verifying time scales poly-logarithmically in n (without demanding quasi-linear proving time) and the N means non-interactive, which means that after a pre-processing phase (which may be non-transparent), the proof system cannot allow any further interaction. Notice that according to this definition a non-succinct trusted setup phase is allowed, and, generally speaking, the system need not be transparent, but it must be noninteractive (after finalizing the pre-processing phase, which is unavoidable).
Looking at the CI-verse (see Figure 5), one notices that some members of it are STARKs, others are SNARKs, some are both, while others are neither (e.g., if verification time scales worse than poly-logarithmically in n). If you’re interested in privacy (ZKP) applications then both ZK-SNARKs and ZK-STARKs and even systems that have neither the scalability of a STARK nor the (weaker) succinctness of a SNARK, could serve well; Bulletproofs, used by Monero, is one such notable example, in which verification time scales linearly with circuit size. When it comes to code maturity, SNARKs have an advantage because there are quite a few good open source libraries to build on. But if you’re interested in scalability applications (where you need to build for ever growing batch sizes), then we suggest using symmetric STARKs, because, at time of writing, they have the fastest proving time and come with the assurance that no part of the verification process (or of setting up the system) requires more than poly-logarithmic processing time. And if you want to build systems that have minimal trust assumptions, then, again, you want to use a symmetric STARK because the only ingredient needed there is some CRH and a source of public randomness.
4. Summary
We're blessed to be experiencing the marvelous Cambrian explosion of the Computational Integrity universe of proof systems, and all bets are that the proliferation of systems and innovations will continue, at a growing rate. Moreover, this attempt to describe the expanding and shifting CI-verse will likely age poorly as new insights and constructions appear tomorrow. Having said that, surveying the CI-space today, the biggest dividing line we see is between (i) systems that require asymmetric cryptographic assumptions - which lead to shorter proofs but are costlier to prove, have newer assumptions which are quantum-susceptible, and many of which are non-transparent, and (ii) systems that rely only on symmetric assumptions, making them computationally efficient, transparent, plausibly post-quantum secure and most future proof (according to the Lindy Effect metric).
The argument over which argument system to use is far from over. But at StarkWare we say: For short arguments, use Groth16/PLONK SNARKs. For everything else, there's symmetric STARKs.
Eli Ben-Sasson, StarkWare
Special thanks to Justin Drake for commenting on an earlier draft.
Footnotes
¹ The term ZKP is often misused to refer to all CI systems, even ones that are not, formally, ZKPs. To avoid this confusion we use the loosely defined terms of “crypto proofs” and “computational integrity (CI) proofs”.
² You can read about STARK arithmetization and low-degree compliance here:
- Arithmetization: blogs [1, 2], lecture slides, and video lecture.
- Low-degreeneess: blog post (for STARKs)
³ The use of univariate polynomials can be generalized vastly, e.g., to multivariate polynomials and algebraic geometry codes, but for simplicity we stick to the simplest, univariate, case.
⁴ We are specifically excluding lattice based constructions from our discussion, because they are not yet deployed in code. Such constructions are asymmetric and also plausibly post-quantum secure, and typically use small (prime) fields.
⁵ A field is k-smooth if it contains a subgroup (multiplicative or additive) of size all of whose prime divisors are at most k. For instance, all binary fields are 2-smooth, and so fields of size q such the q-1 is divisible by a large power of 2.
⁶ Nielsen’s law of Internet bandwidth states that user bandwidth grows by 50% per year. This law fits data from 1983 to 2019.
⁷ Other systems (like PLONK) use pairings only to obtain a (polynomial) commitment scheme, and not for arithmetization. In such cases, arithmetization may lead to any low-degree constraints.
⁸ Formally, “quasi-linear in n” means O(n logᴼ⁽¹⁾ n) and “poly-logarithmic in n” means logᴼ⁽¹⁾ n.
