
We'll now begin our foray into cryptography. Cryptography is a deep and vibrant field, and there's a lot more to it than we can cover in a single module. But the next four lessons should equip us with the building blocks we need to understand cryptocurrencies.
The first and most important building block for any cryptocurrency is the hash function. Hash functions are used in almost every component of Bitcoin, so in this lesson we'll explore this cryptographic primitive in depth.
What is a hash function?
A hash function is a function that deterministically maps an arbitrarily large input space into a fixed output space. That's a pretty abstract description, so instead I like to imagine a hash function as a fingerprinting machine. It takes in an input (often a string of characters) and returns a corresponding cryptographic "fingerprint" for that input (often another string of characters). That fingerprint is should be unique to that input, but if you were given some random fingerprint, you shouldn't be able to figure out the original input that produced the fingerprint.

The input to a hash function is usually called the preimage, while the output is often called a digest, or sometimes just a "hash." You may have come across terms like SHA-2, MD5, or CRC32. These are names of common hash functions.
All good hash functions have three important properties:
First, they are deterministic. This means that given the same preimage (input), a hash function always produces the same digest. The digest may be "random-looking," but it's completely deterministic. sha1("foo") should output 0beec7b5ea3f0fdbc95d0dd47f3c5bc275da8a33, now and forever.
Second, a hash function has a fixed output size. For SHA-256, every hash digest is exactly 256 bits. Different hash functions have different output sizes: MD5 digests are always 128 bits, while SHA-1 hashes are 160 bits.
Third, hash functions should be uniform, meaning the digests should be distributed uniformly over the output space. Imagine a histogram of your outputs—you want your digests spread evenly across all possible values.
You can try out a hash function yourself in a Python3 REPL using the following code:
from hashlib import sha1
sha1(b"your string here").hexdigest()(Remember to include the b prefix to your input so Python3 knows to treat it as a bytes object rather than a string. Otherwise the hash function will complain.)
Good hash functions tend to have complicated inner workings. But we can build a crappy hash function pretty easily. Here's one:
def hash(n):
return n % 256This only works with numbers of course, but we could make it work with strings by interpreting any string's bytes as one giant number and feeding it into this function.
This function technically satisfies all three hash function properties: it's deterministic, the output size is fixed (0-255), and given large random inputs, the digests will be uniform. Just don't use it in a real application!
There are many data structures that require hash functions internally, such as hash maps. For most of these data structures, the inputs are not expected to be adversarial; i.e., no one is trying to break your hash map. But if you need stronger security (like Bitcoin does), you should use a more robust subset of hash functions known as cryptographic hash functions.
You would not use a cryptographic hash function in a hash map, since cryptographic hash functions pay for their security with worse performance. But if you're looking for security, only a cryptographic hash function will do.
Cryptographic hash functions
Cryptographic hash functions come with three additional requirements over normal hash functions.
The first requirement is that a cryptographic hash function should be one-way. This means that given a digest, it should be computationally intractable to invert the hash function and compute its preimage. For example, given 88ebe8bf78169fcfe6d8a68b040ca600284bacd3, there should be no way to figure out the preimage was grandma, other than by brute-forcing potential inputs. This is not technically true for all hash functions—for example, checksums like CRC32 and locality-sensitive hashes are easily invertible.
The second requirement is that a cryptographic hash function should exhibit an avalanche effect. The avalanche effect basically says that if any single bit changes in the preimage, it should trigger an "avalanche" that jumbles the other bits. Thus, two very similar inputs that differ in only one bit should have no discernible relationship between their outputs.
You can see that SHA-1 has strong avalanching properties:
import binascii # to convert binary to ASCII bytes
from hashlib import sha1
sha1(binascii.b2a_uu(b"11111111")).hexdigest()
# 'a31518892830eec9ea21762e8bb101ce13890aee'
# let's flip a single bit and see what happens
sha1(binascii.b2a_uu(b"11011111")).hexdigest()
# 'c68b4d1bb5154c76370f33895d5d9350a4c73ba9'The last property that a cryptographic hash function needs is collision-resistance. When two inputs hash to the same output, that's known as a collision.
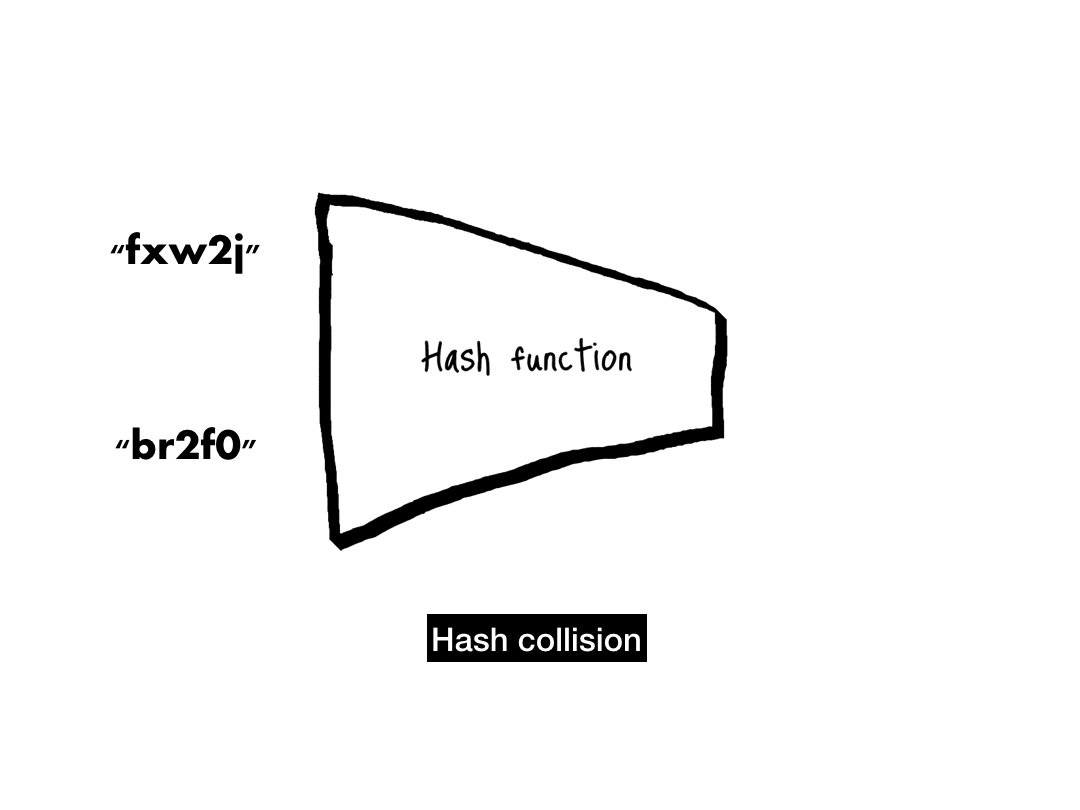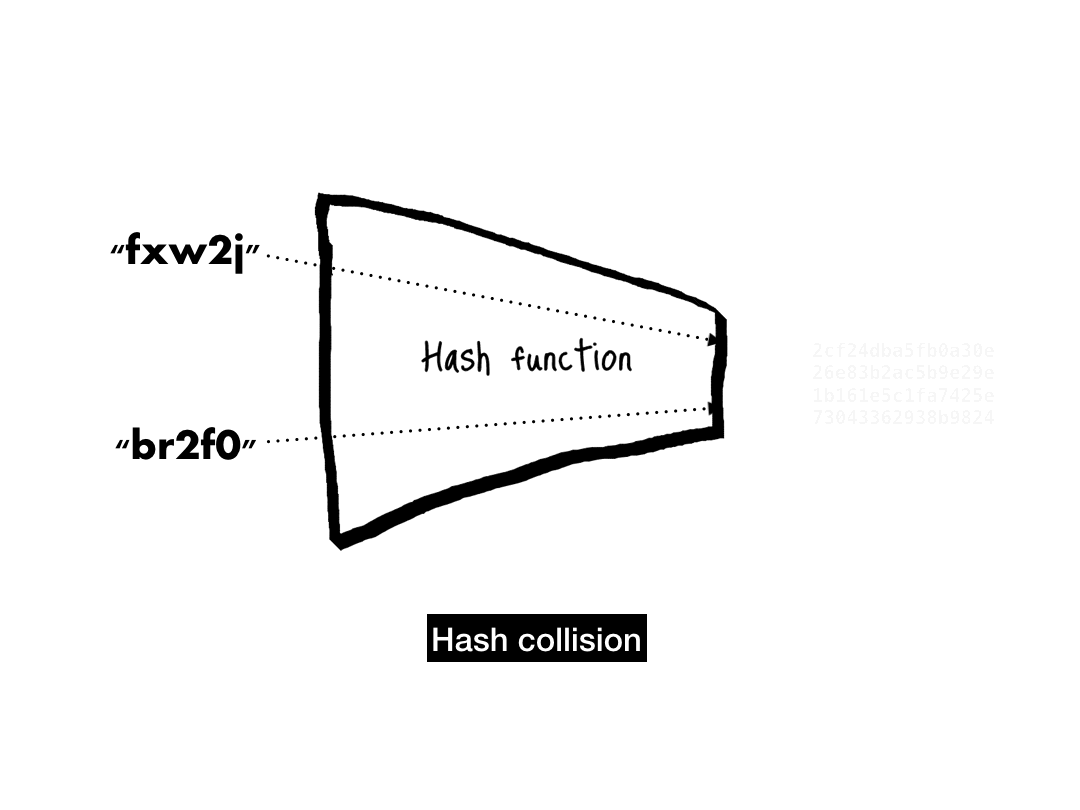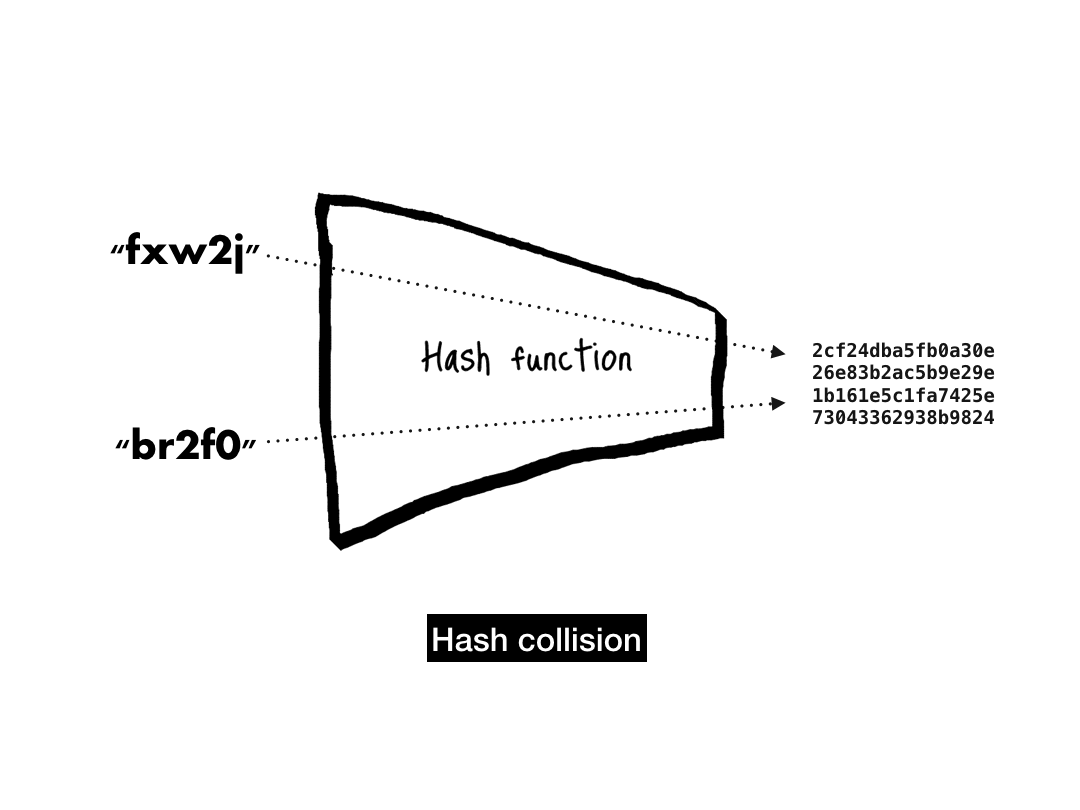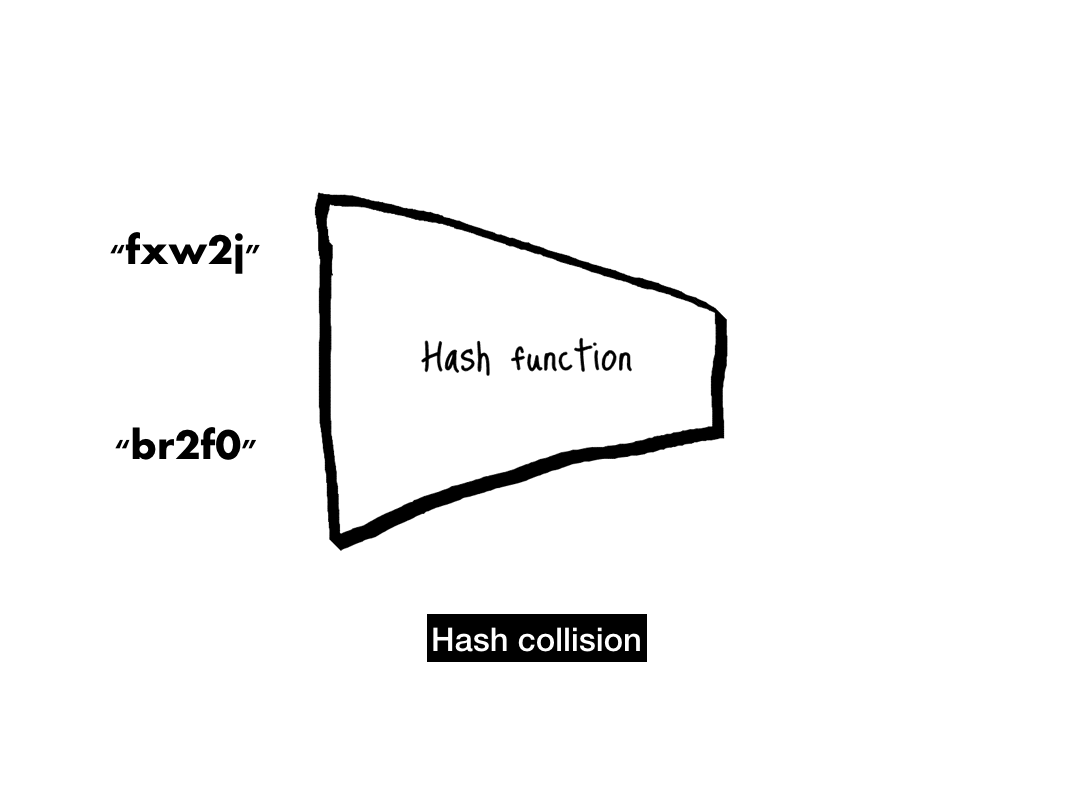
We never want to see a collision—they are the first sign that a hash function is broken. Given how deeply hash function security depends on collision-resistance, let's take a deeper dive into this property.
Collision-resistance
Our hash function of def hash(n): return n % 256 is not very collision-resistant. This should be obvious when you realize how small its range is: there are only 256 possible digests. Note that we generally measure ranges in the number of bits, in which case our function would have a range of 8 bits, for \(2^{8}\) possible values.
With a range this small, we could guarantee a hash collision by simply iterating through 257 inputs. By the pigeonhole principle, we will have to see at least one collision.
You can scale this argument up. Even for a hash function like SHA-256, which has a range the size of \(2^{256}\), if you tried \(2^{256} + 1\) numbers, you'd have to get at least one collision. Thus, we know that all hash functions must have collisions—after all, all hash functions have finite output sizes, yet infinitely many possible inputs.
But for all practical purposes, \(2^{256}\) is so big that it's effectively unenumerable. For comparison, the number of atoms in the universe is roughly \(2^{260}\). So while we know that collisions must exist, we're never going to find one in the lifetime of the universe—and, indeed, a collision has never been found for SHA-256.
So how much collision-resistance do we need? The frontier of computational tractability today is roughly around \(2^{80}\). Below that, it's plausible that a powerful enough actor could brute-force your cryptography. Add some extra headroom for a couple decades of future-proofing, and that rounds us up to 128-bit security as a good rule of thumb.
So if we want to increase the size of our range, we could level up our hash function! Instead of n % 256, instead we'll do:
def hash(n): return n % (2 ** 128)Now we have a range of \(2^{128}\). Problem solved, right?
Of course, even with this beefed up range, we don't actually need to brute-force this function to produce a collision. We can find one analytically—that is, by reverse-engineering the structure of the function. Knowing the function n % (2 ** 128) wraps around after \(2^{128}\), we can manufacture a collision by simply adding \(2^{128}\) to any number. Thus, \(0\) and \(2^{128}\) would both collide to \(0\).
So collision-resistance is not just about the size of the range, it's also about the structure of the hash function. This is why robust cryptographic hash functions are harder to build than normal hash functions. For example, while CRC32 is a fine checksum, it's not suitable as a cryptographic hash function. Thanks to its simple mathematical structure, it's trivial to analytically generate collisions for CRC32:
from zlib import crc32
crc32(b"squeamish ossifrage") == crc32(b"deltaTvJZx")
# True
crc32(b"buckeroo") == crc32(b"plumless")
# TrueGenerating a collision
It's not hard to imagine why we want to avoid collisions. If I know the hash of a program you intend to install is d306c9f6c5..., if I generate some other file that hashes to that value, I could wreak all sorts of havoc.
We saw that we can use analytic methods to generate collisions for simple hash functions like n % (2 ** 128). But for more robust hash functions, you might assume you'd have to use brute-force: keep trying two random inputs at a time until they collide. For a 128-bit hash function, this should take \(2^{128}\) tries.
But it so happens that for any hash function you can always do better than brute-force. This is a consequence of a simple technique known as a birthday attack, so-named after a famous statistical paradox known as the birthday paradox.
The birthday paradox goes like this: on average, how many guests need to be at a party so that two guests will share the same birthday?
The answer is, surprisingly, 23. At 23 guests, there is a 50.7% probability that two people share a birthday. At 70 guests, it is 99.9% likely that two share the same birthday.
Why?
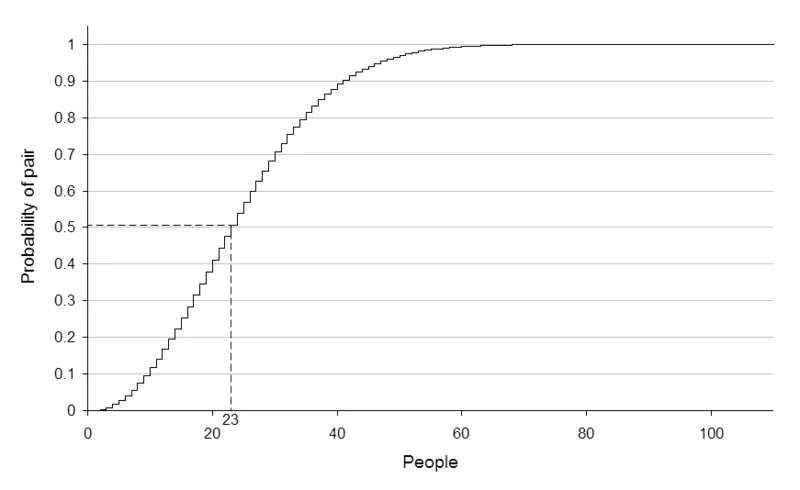
You can grasp the intuition if you realize that sharing a birthday is a pair-wise relationship, and pairs grow quadratically. So 23 guests means there are \(253\) possible pairs, each of which has a \(\frac{1}{365}\) chance of sharing a birthday. (Recall that the number of unique pairs among \(n\) elements is \(\frac{n(n - 1)}{2}\).)
\(\sqrt{n}\) turns out to be a good approximation for the 50% likelihood threshold for a birthday collision. This analysis applies to hash functions just as well. For a 128-bit hash function, you should be able to find a collision using a birthday attack in \(O(\sqrt{n})\) time. (This also requires maintaining a table of \(O(\sqrt{n})\) space, since you need to remember every hash you've previously looked at so you can compare all pairs.)
The birthday attack has many important implications, not least of which being our computational security threshold. Remember how we claimed that \(2^{128}\) security is a good default level of security? The birthday attack is one reason why we don't use 128-bit hash functions—otherwise they could be attacked by simply enumerating over ~\(2^{64}\) iterations (plus \(2^{64}\) space). Instead, if we want 128-bit security, we need a 256-bit hash function.
MD5 has 128-bit digests, so hypothetically it should have 64-bit security against birthday attacks. That's weak enough to be brute-forceable. But this is only the upper bound of security—if there are weaknesses discovered in the hash function, an analytic attack can make this even easier. In fact, attacks have been discovered that can produce MD5 collisions in roughly \(2^{24}\) complexity. That's about 16 million iterations, which can be done in less than a minute on a laptop. The MD4 hash function, MD5's predecessor, can have collisions generated by hand.
Collisions are scary. But a collision alone is usually difficult to weaponize in the real world. If the preimages an attacker generates are random and can't be tailored to a specific application, the colliding preimages will probably both just be random garbage. More often, a collision is a sign that the hash function is weakening, and soon people will be able to perform more powerful attacks against it.
Cryptographic hash functions only get weaker over time as cryptanalysts develop attacks against them. MD5 is now considered broken and should not be used in any new software. SHA-1 has recently joined MD5 in the cryptographic scrap heap: it has a small digest size (160 bits), and Google researchers demonstrated a collision against it in 2017. Then in January 2020, the first practical chosen-prefix collision was demonstrated against SHA-1, rendering it completely unusable.
SHA-2 is still considered a strong hash function, and is the default hash function for many cryptographic applications. It also happens to be the major hash function used in Bitcoin and in many Bitcoin-derived cryptocurrencies. In the next two lessons, we'll explore important components of Bitcoin that are built on top of SHA-2: Merkle trees and Hashcash. You should now be equipped to understand why they work.
Assignment
For your first coding assignment, you'll be producing a hash collision in a new hash function we'll call MD1.25. This hash function is just defined as MD5 truncated to the first 4 bytes (the first 8 hex digits). Thus, MD1.25 only has a digest size of 32 bits (\(\frac{1}{4}\) of MD5). You should be able to produce a collision in no more than a couple seconds.
You can access the assignment here.
If you don't have a Repl.it account, first you'll need to sign up. It should be really quick—see the video below for a walkthrough of the platform.
Fork the repo and get cracking.
Once you've got all the tests passing, you should be ready to move on.
Additional reading
- The First 30 Years of Cryptographic Hash Functions and the NIST SHA-3 Competition by Bart Praneel (2010)
- Lessons From The History Of Attacks On Secure Hash Functions by Zooko Wilcox (2017)
- 64 Bits ought to be enough for anybody! by Artem Dinaburg (2019)



