
Gnutella was one of the very first decentralized file sharing protocols to emerge after the death of Napster. It was most popularly implemented in the file sharing application LimeWire.
As a fairly simple gossip-based P2P protocol, Gnutella's networking design is a good blueprint for understanding Bitcoin. In this lesson, we'll start by delving into the theory of gossip protocols. We'll then cover Gnutella's design. Then, in the assignment, you'll get to build your own Gnutella-esque protocol.
Gnutella is a great entrance point into gossip because it's one of the simplest gossip protocols that was used in production. But gossip protocols have been around since the 90s, and have been used in many systems such as wireless networks, sensors, and of course, in internet routing. Today many distributed databases like Cassandra, Riak, and Voldemort use gossip to propagate internal state updates.
So why choose gossip? What does it accomplish?
Distilled to its essence, gossip simply a way to do decentralized message propagation.
The multicast problem
You're probably familiar with the term broadcast. A broadcast is sending a message to every node in a network. A multicast is when you want to send a message to many parties, but not everyone in the entire network. If you want to perform a search query in a P2P file sharing network, you actually don't want to send it to everyone in the network—if you did, the network would quickly get overloaded. Only a subset of the network needs to actually respond to our query.
So what's the best way to perform this multicast?
The first thing you'd think of is probably just to iterate through everyone you want to reach and send them a point-to-point message.
def simple_multicast(recipients, msg):
for recipient in recipients:
recipient.send(msg)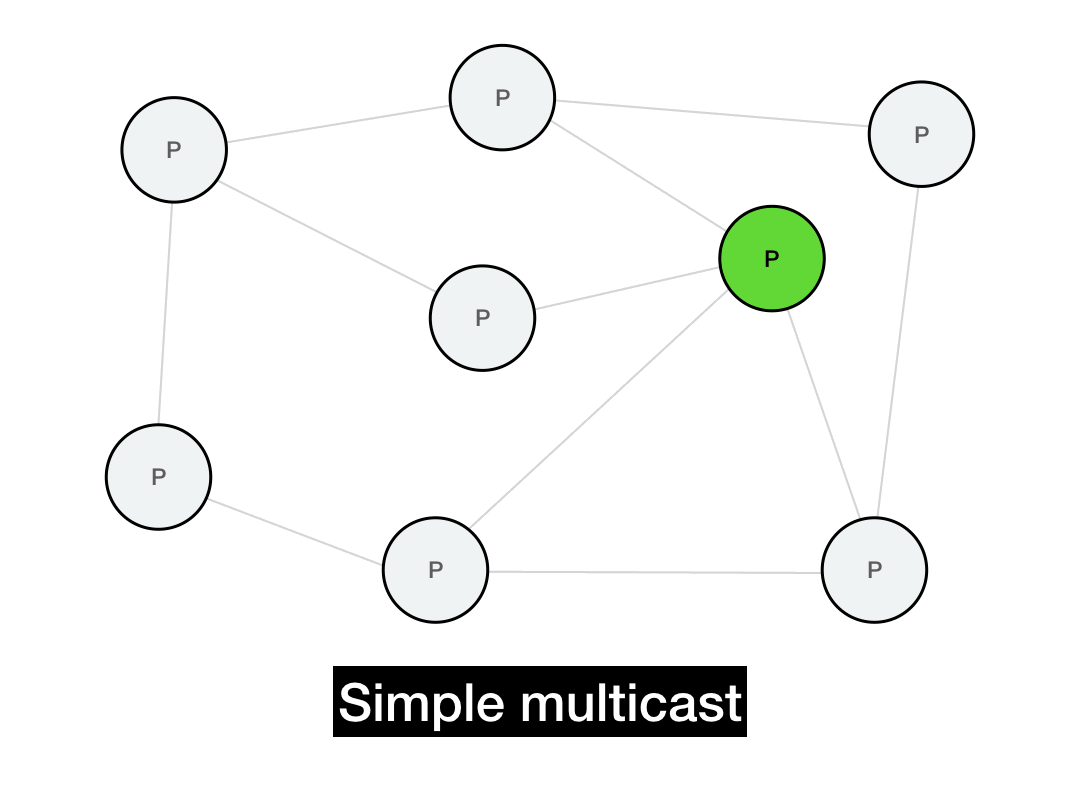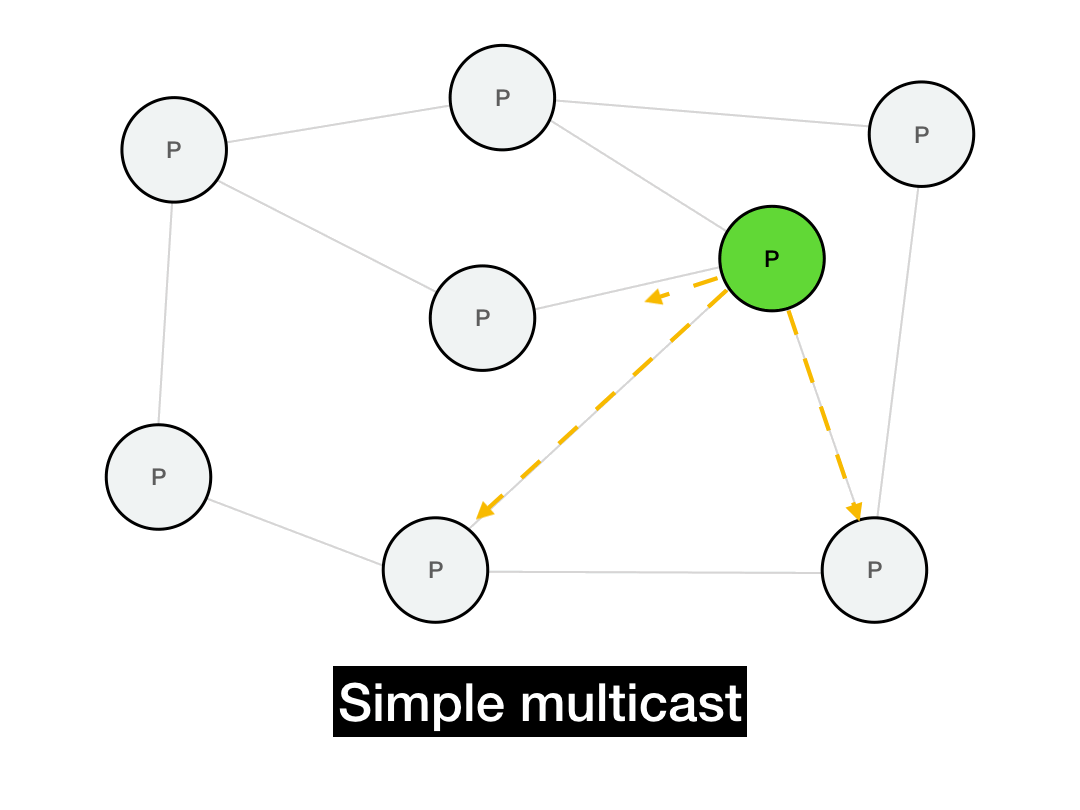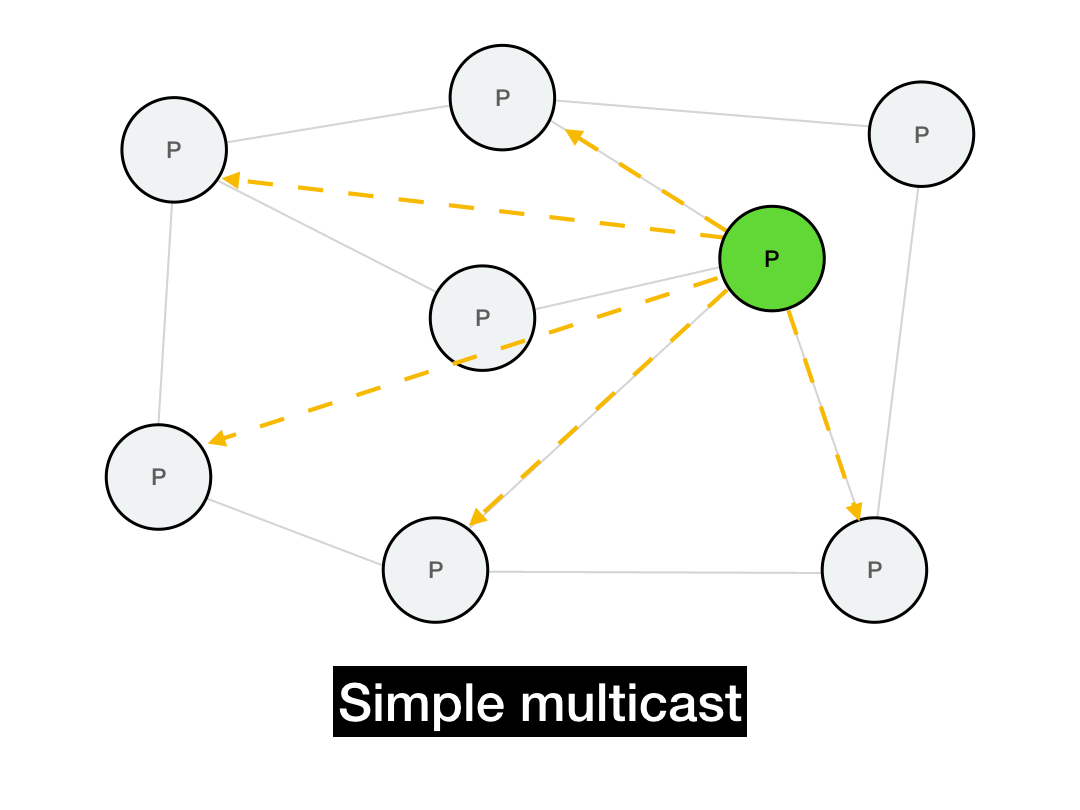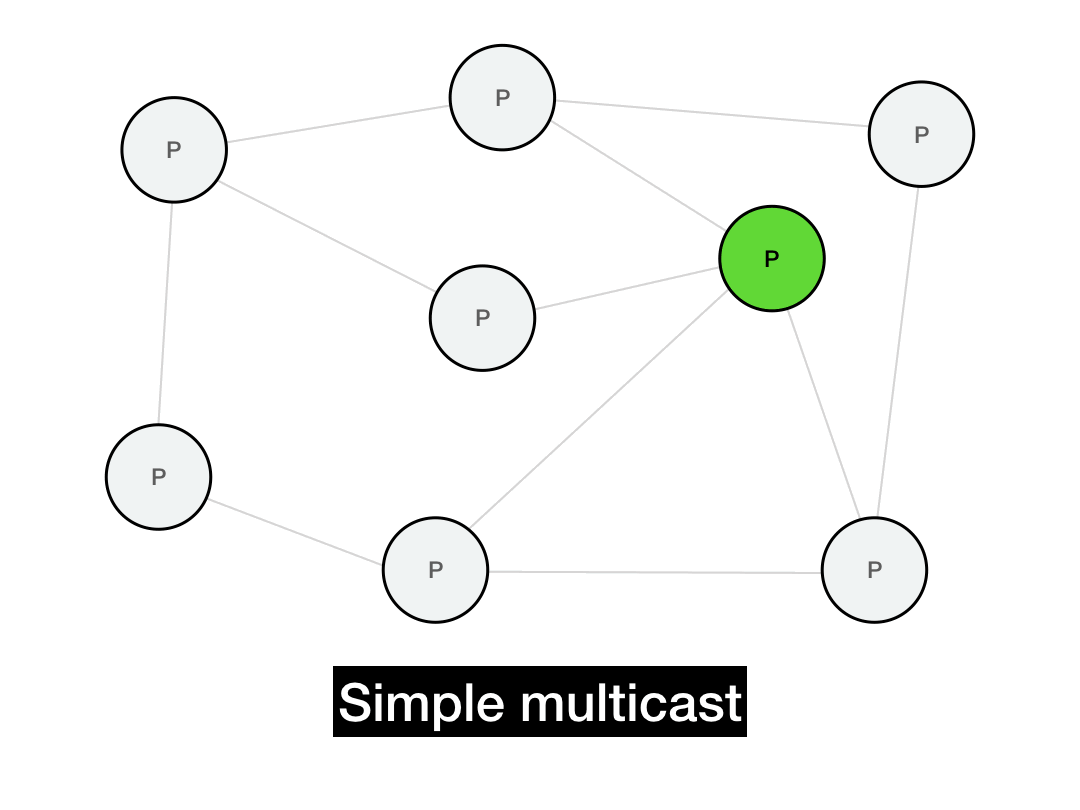
This works, but it's not very efficient. It takes \(O(N)\) time to perform the full multicast. It's also not realistic: it requires everyone in the network to maintain a list of every other node in the network. In a P2P system, this list can be huge and will change all the time due to node churn. (Plus, if the sender fails in the middle of this long multicast, the entire operation will fail.)
So how can we improve on this?
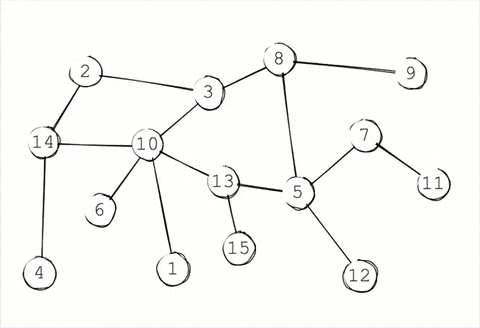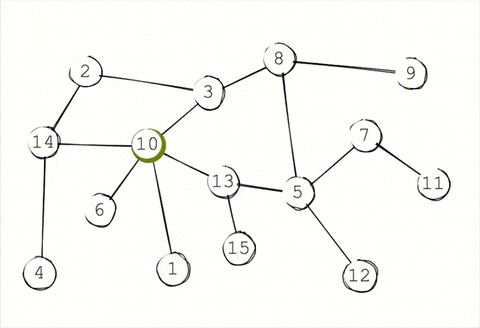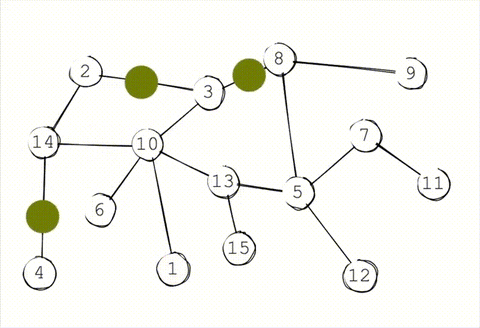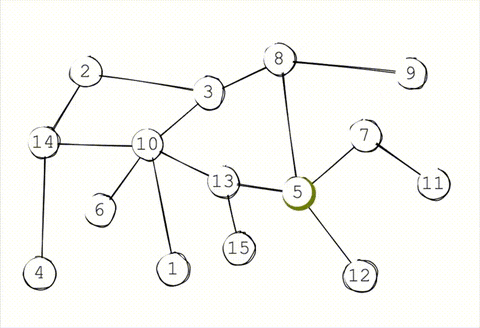
One way to optimize message propagation is by building a minimum spanning tree. A spanning tree is a tree that covers every node in a graph. A minimum spanning tree is the smallest possible such tree—in other words, a spanning tree that is built with the minimum number of edges (or minimal total edge weights).
Below is a minimum spanning tree for this graph. If we're trying to broadcast a message from the green node, then all of our messages would be routed along this tree. (There are multiple such spanning trees with height 2, this is just one of them.)
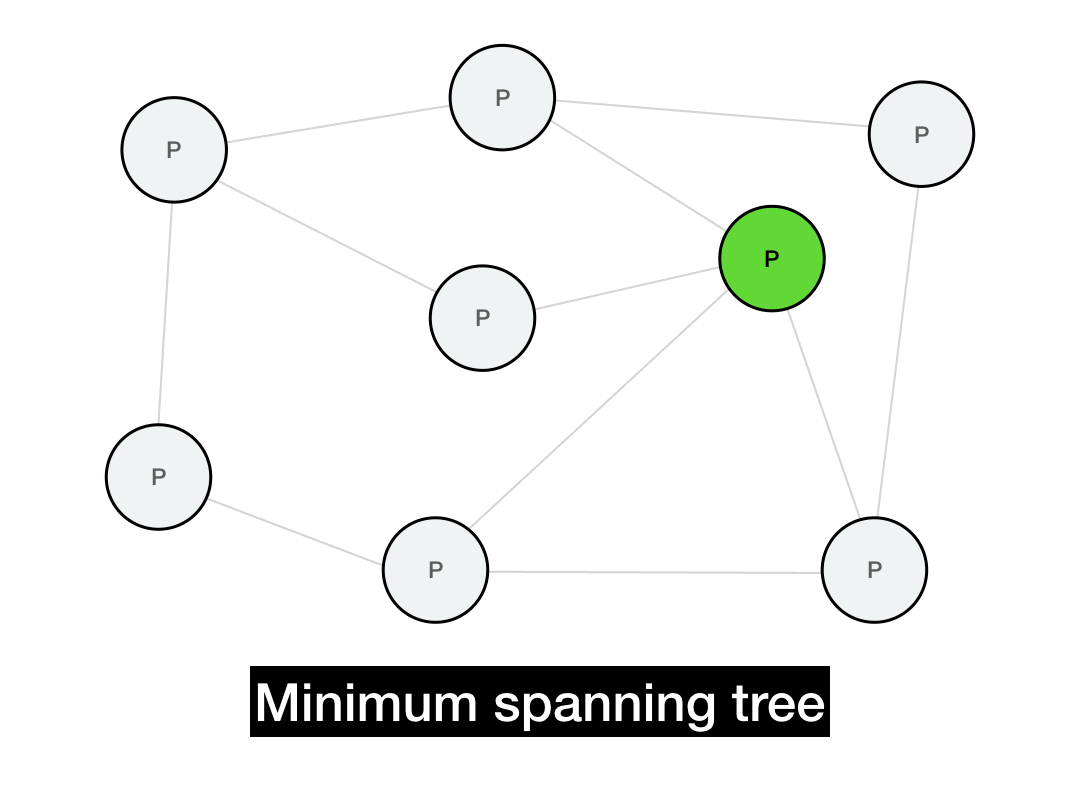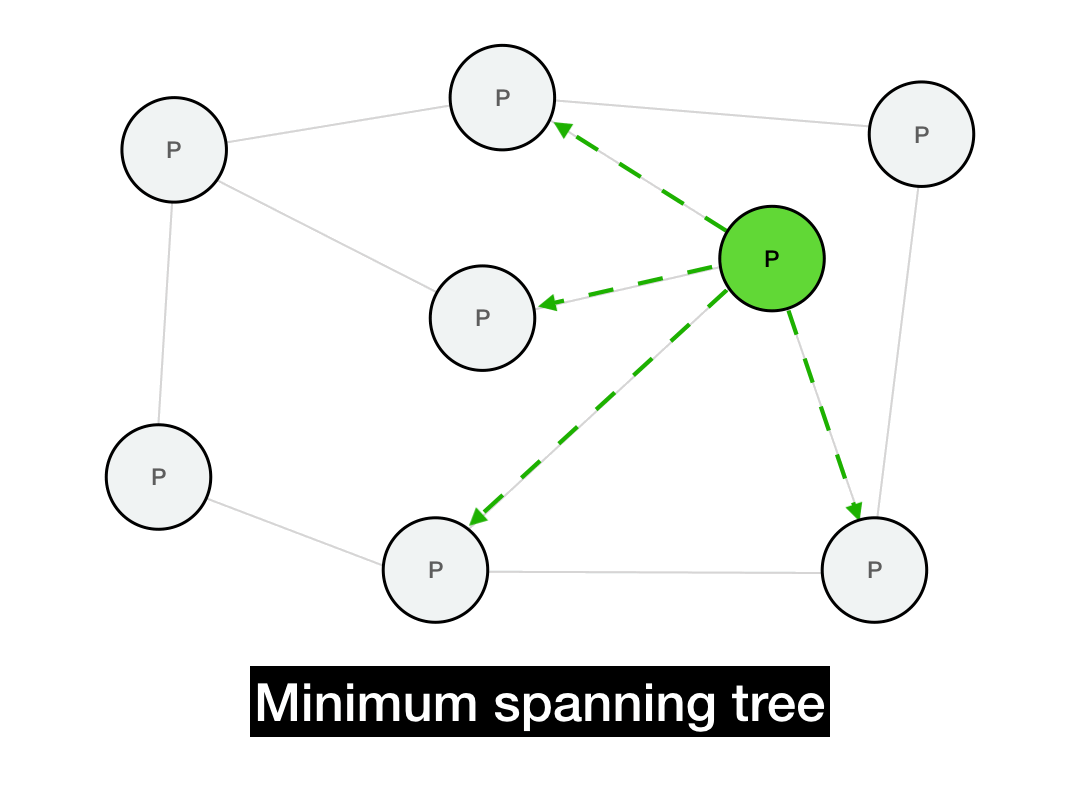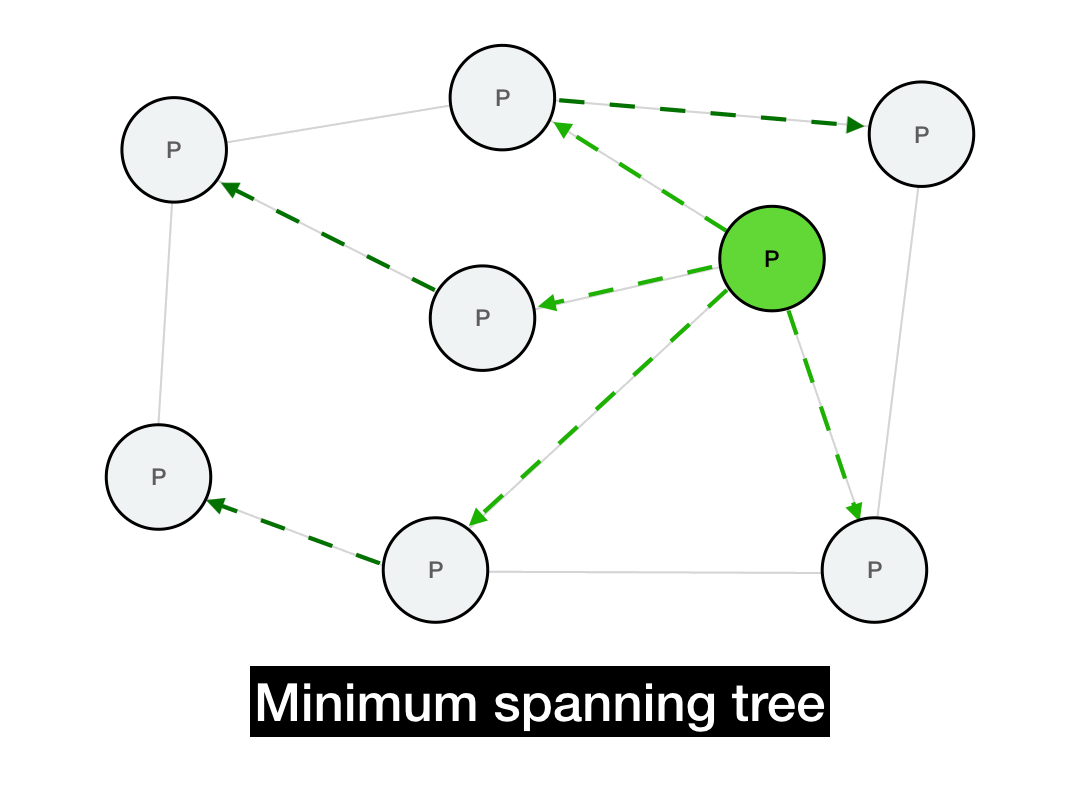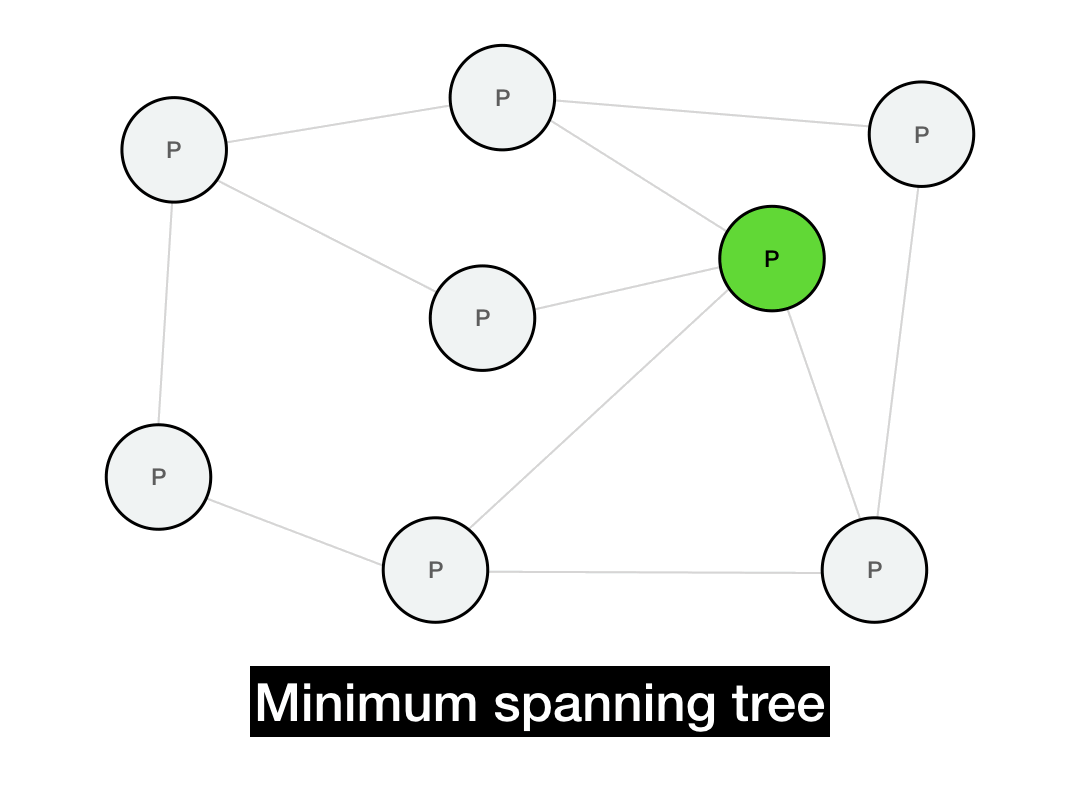
This should implement a broadcast in only \(O(\log{N})\) hops, since the messages will propagate in time proportional to the depth of the tree. Additionally, every node will only need to perform a small number of operations in that broadcast, instead of the sender performing a single massive \(O(N)\) operation (which would be infeasible for a large network).
This is nice! So nice, in fact, that it's theoretically optimal. A minimum spanning tree gives us maximally efficient routing, especially if the spanning tree is constructed in consideration of the underlying network topology.
But there's a big problem with spanning trees: they're extremely brittle. If even a single node faults or churns out of the network, entire arteries of the tree will get knocked offline and become unreachable. In a P2P setting, we have to assume that nodes will crash, packets will be dropped, and the network topology will change over time. A spanning tree is great for when the network is static, but in a P2P network, it's a non-starter.
Enter the gossip protocol
If we want the scalability of a spanning tree without the brittleness, we want to use gossip. Gossip protocols are simple in principle, and you probably already have the intuition of how they work.
In a traditional gossip protocol, each node periodically gossips to \(K\) random targets. This \(K\) is known as the infection factor (as a nod to epidemiology). Once those \(K\) targets receive the gossip, they randomly select another \(K\) targets to gossip to. This continues until either all reachable nodes receive the message, or the message expires.
The more aggressive the infection factor, the faster and more completely the message propagates. On the other hand, the higher the infection factor, the more noise gets created in the network and the more bandwidth gets consumed per message.
If a node gossips to all of their peers, it's known as flooding. Bitcoin performs flooding rather than random infection.
Like many randomized protocols, gossip is imperfect, but it ends up approximating the properties of a minimum spanning tree (with high probability). At the same time, it offers much higher fault-tolerance.
Gossip protocols have several desirable properties for a P2P network:
- Reliability (only a small fraction of intended recipients will not receive your broadcast)
- Low latency (\(O(\log{N})\) rounds for a message to disperse through the network)
- Low message load per node
- Very high fault-tolerance (at 50% node failure, it only requires twice as many rounds of gossip)
This makes gossip a prime candidate for message propagation in a system like Bitcoin.
So with a little bit of gossip theory under our belts, let's look at how Gnutella works beneath the hood.
The Gnutella protocol
The design of Gnutella started with a simple idea: let's take a file sharing system like Napster, but remove the central server.
Napster, you'll recall, had a central server (or set of servers) that operated as a search engine over all of the available files and allowed peers to find each other. In Gnutella, the P2P swarm will itself handle search requests and peer discovery.
In Gnutella, each client serves double-time as both a client and server (Gnutella calls them "servents"). The clients connect to each other through directly through a P2P overlay graph.
The overlay graph is the P2P network that is "overlaid" on top of the actual underlying network. The underlying network in this case is IP itself—that's how nodes have to literally send packets to each other. In the underlying network (also known as the underlay), two IPs that share a large prefix will be physically close to each other.
But the P2P overlay graph doesn't necessarily respect the underlying distance. Nearby peers in the overlay graph might be far away in the physical world, and neighbors in the real world may be far away in the P2P graph.
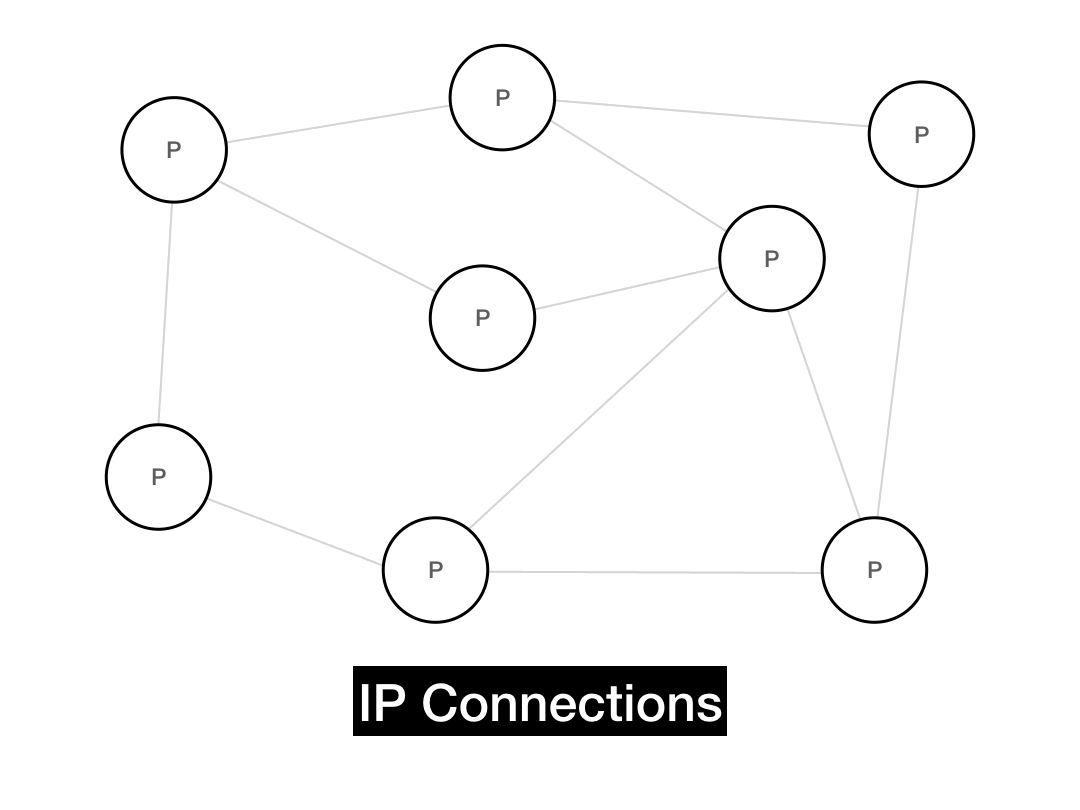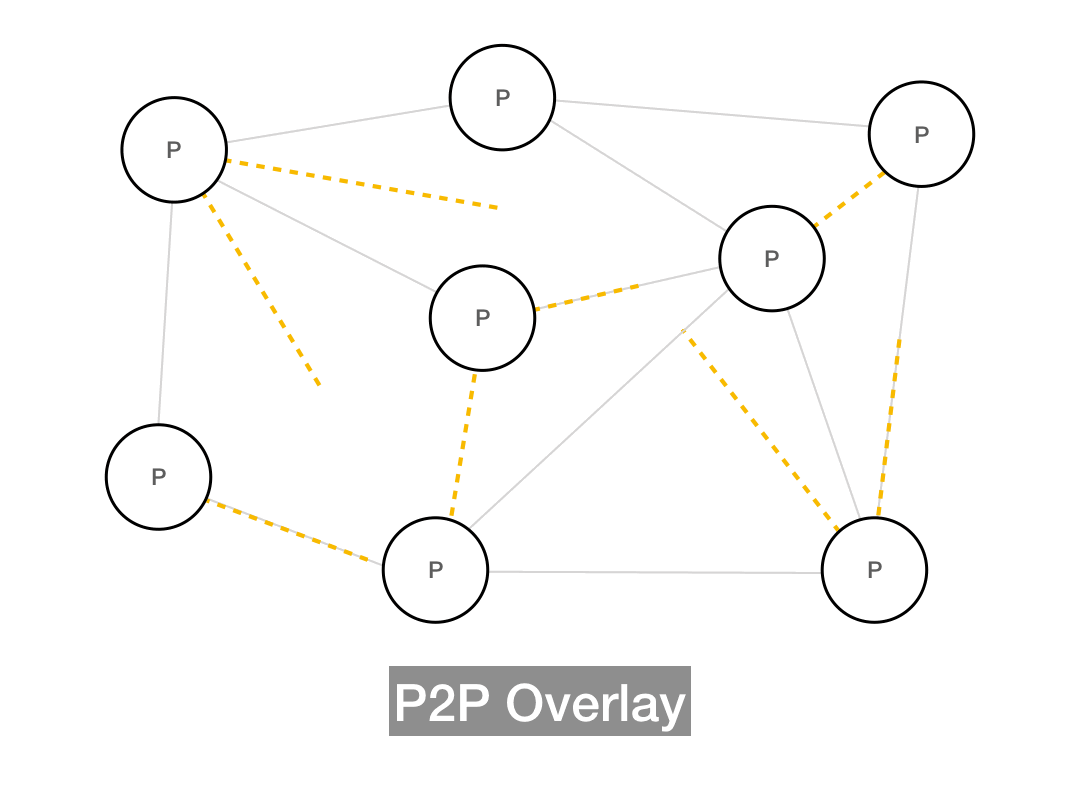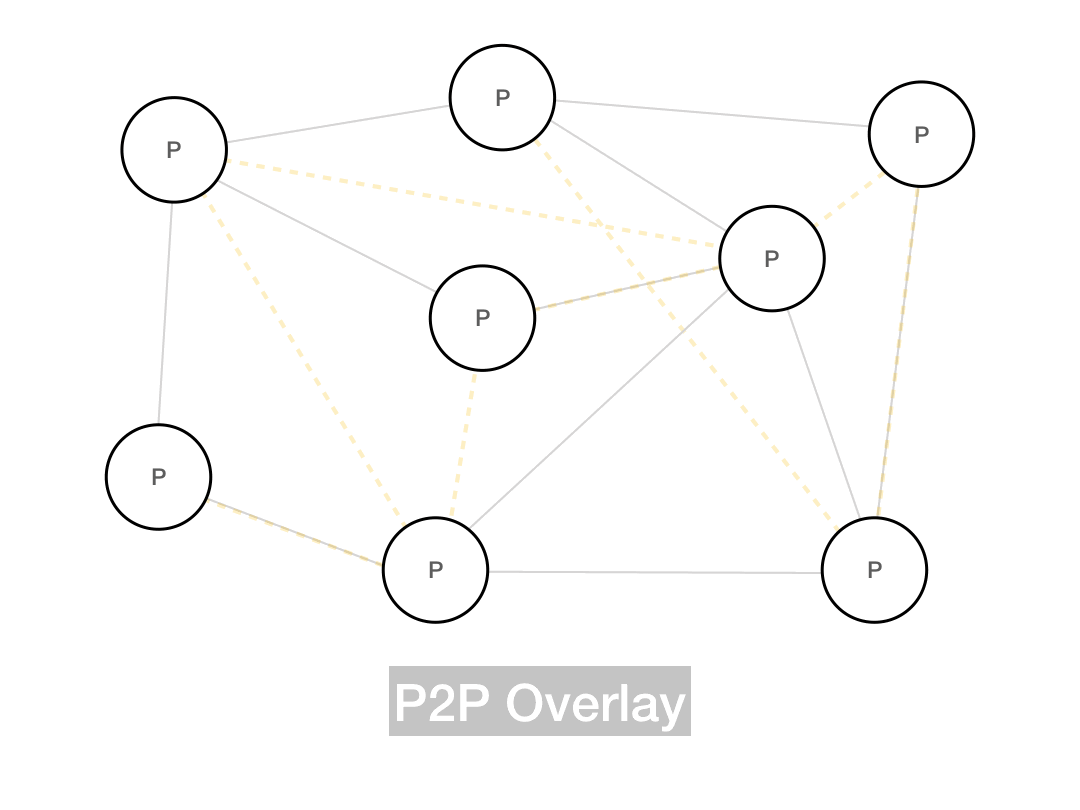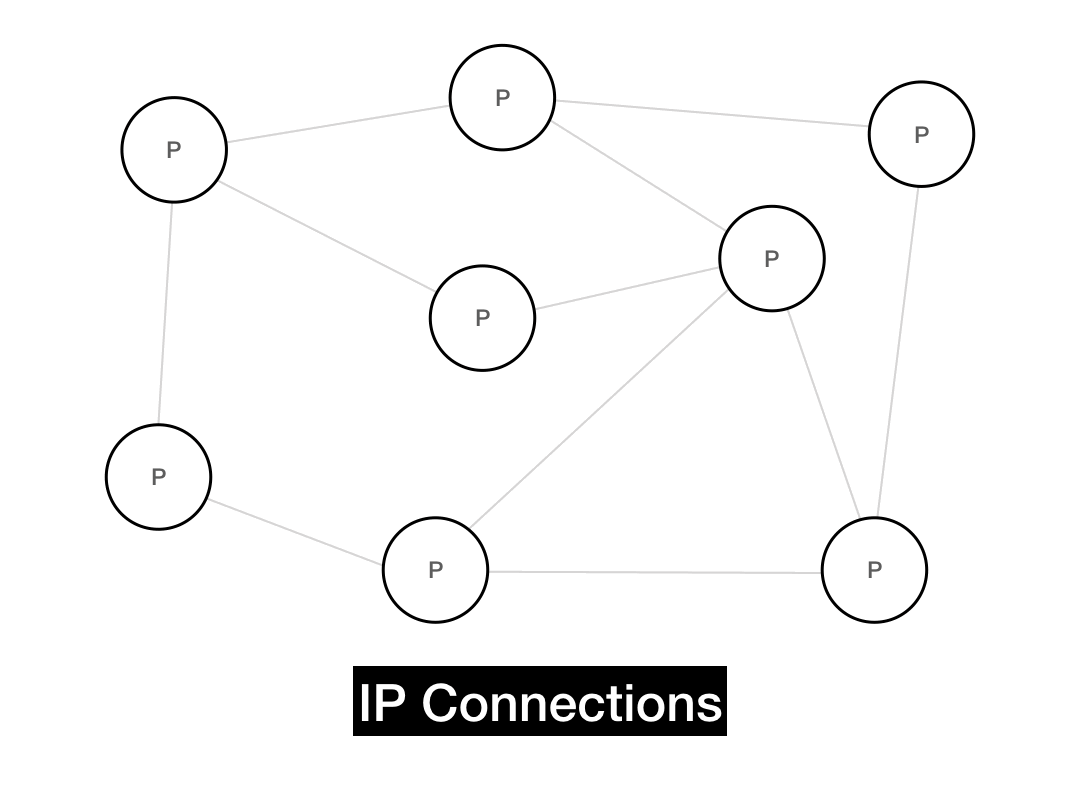
Whenever the overlay network is insensitive to the underlying network topology, you're going to get suboptimal routing, since messages aren't taking the real world shortest path. More advanced P2P systems try to use smarter routing models which take the underlying network into account, but the simplest possible approach is to build an unstructured network, which produces its own random topology and follows that when it comes to message routing. Gnutella is an unstructured network, as is Bitcoin (with some caveats we'll address later).
A sketch of the protocol
By now you've gotten the high-level idea of how Gnutella works. Let's delve into the finer details.
In Gnutella, each node keeps track of a list of peers (for simplicity, let's say no more than 5 peers each). Every node periodically pings its peers to ensure they're still online. If a node notices any of its peers have gone dark for too long, the node will un-peer with them and find someone else peer with.
There are five message types in the Gnutella protocol:
| Message type | Description |
|---|---|
Query |
A search for a certain filename |
QueryHit |
A positive reply to a search, stating "Hey, I've got a file that matches that Query" |
Ping |
Probing a peer to see if they're alive |
Pong |
A reply to a Ping |
Push |
Requests a file be sent to the requester (in case the file owner is behind a firewall that blocks incoming connections) |
That's all. There's a lot you can do with just these five message types!
The Ping and Pong are used for peer discovery and heartbeating, so let's ignore those for now. The Push message is only for coordinating file downloads when the file owner is behind a firewall, so ignore that as well. The meat of the protocol occurs in Query and QueryHit messages.
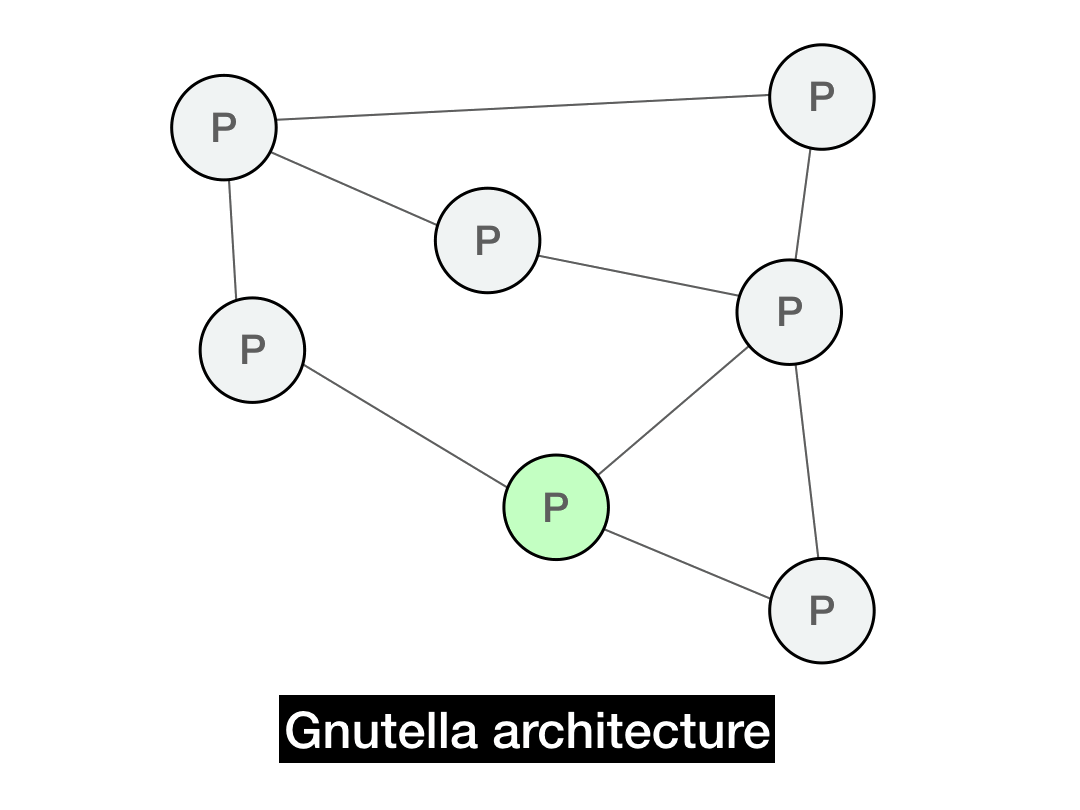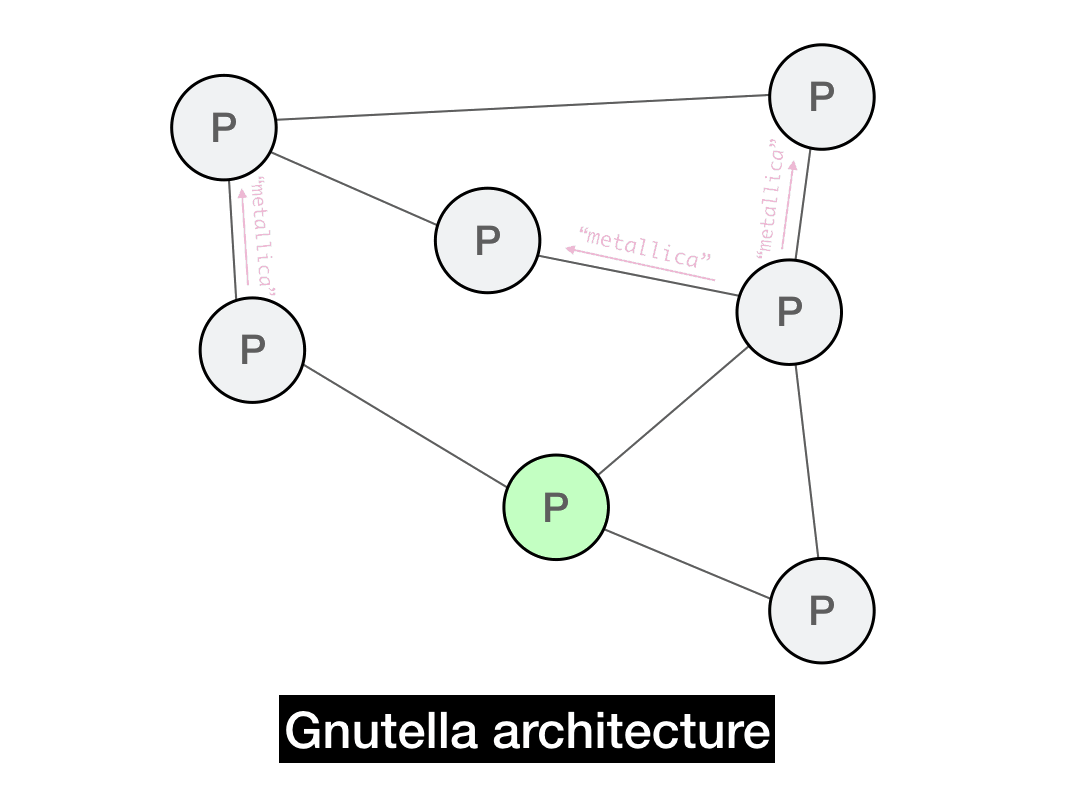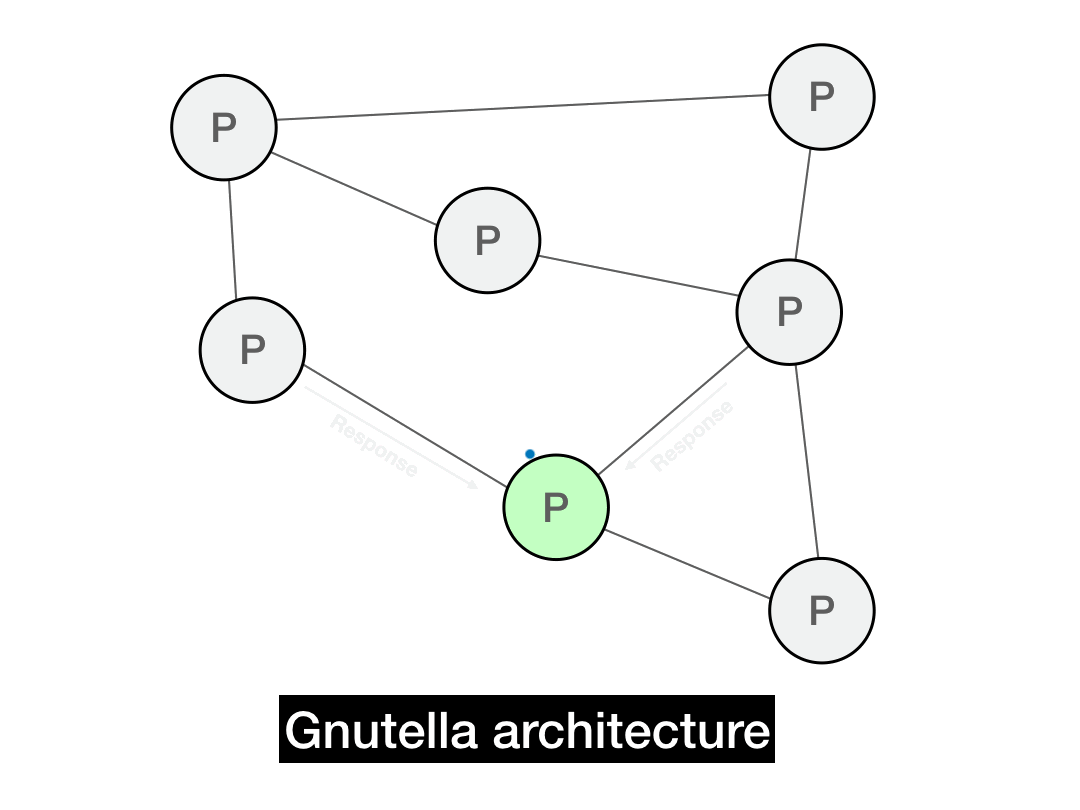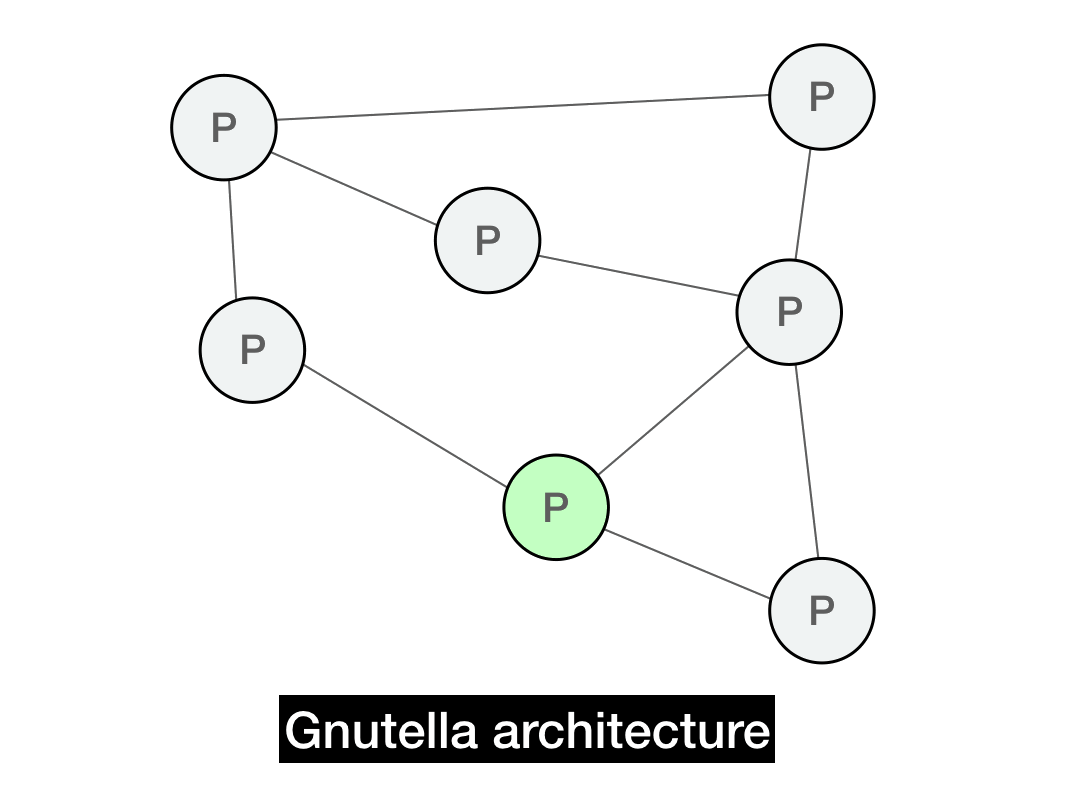
Let's say you're looking for a Metallica song, so you construct a Query message. You want to disseminate your query widely, so you gossip this query to a random 3 of your peers. Each of those peers also gossip the query to a random 3 of their peers, and so on.
Note that if this forwarding process were to continue indefinitely, we'd have a problem: your message would loop around in the network forever. Node \(A\) would send to \(B\), \(B\) would send to \(C\), \(C\) would send back to \(A\), and so on. This is obviously not what we want—we need some form of memory so a node can discard messages that it's already seen.
To solve this, we'll give each message a UUID. By simply keeping track of UUIDs you've already forwarded, you can ignore repeat messages and thus prevent any infinite message loops.
But there's still an issue: every message will propagate through the P2P network until it reaches literally everyone. This is fine if you want that, but it's overkill for file sharing. This would rapidly become a scalability bottleneck (every node would literally have to handle every single search in the whole network).
To solve this, we can add a TTL (time-to-live) on every message. The TTL is an integer that is decremented each time the message is forwarded—once the TTL hits 0, the message is discarded. This means each message will only travel so far before disappearing, like a decaying wave.
With these things implemented, we should get some nice gossip-like message propagation with searches localized within the network.
Routing QueryHits
Now let's take the other side: say we receive a Query for metallica and we've got a file that matches. We want to return them a QueryHit response. How should we route the response back to the original sender?
The most obvious thing to do is have the searcher include their IP in their query so we can respond directly to them, sort of like a return address.
What's wrong with this? (Really think about it.)
The problem is this lets passive observers know exactly which IPs were requesting which files. This would be a huge privacy leak! We should try to be a little more discreet than just broadcasting the source IP for every search.
Perhaps the responder could gossip out their IP, which would hopefully let the sender know who to reach out to. But then this would violate the privacy of the responder! It also leads to lots of unnecessary noise in the network, since everyone else has to gossip back the IP of the responder, even though only the sender actually cares.
The solution that Gnutella uses is quite slick: route the response back recursively.
Say you have a file that matches a Query for "metallica". You send back a QueryHit response back to whoever forwarded you that message, specifying the UUID you're responding to. We'll say you got forwarded it by node \(C\). Node \(C\), on seeing a QueryHit for that UUID, will send it back to whoever forwarded them the query, node \(B\). Node \(B\) will then route it back to node \(A\), the original sender. By simply having each node remember who forwarded them each message, QueryHits can be recursively routed back to the originator. This minimizes privacy leakage and unnecessary noise in the network.
This functionality between Query and QueryHit messages is the core of Gnutella's file discovery. Actual downloads then take place through direct HTTP connections.
As you can see, Gnutella is an elegant, simple file sharing protocol that works without a central party.
The problems with Gnutella
Despite its ingenuity, Gnutella had its share of problems. The first problem was in bandwidth: Gnutella created a huge amount of network of traffic, roughly 50% of which was just pings. Some of this could be mitigated with aggressive caching and consolidation of ping messages, but early versions of the protocol were very bandwidth-intensive.
The second problem was that 70% of Gnutella users were freeloaders who only ever downloaded files and never uploaded any of their own. This made for an unhealthy balance between downloaders and uploaders.
Lastly, Gnutella was not actually a great candidate for this kind of gossip-based network design. In Gnutella, more than half of the network received every single query. This is overkill for file sharing, where you don't need that large a portion of the network to receive each message—most searches are for common files, which many nearby nodes can serve you.
Bitcoin, on the other hand, requires every node to know about every block, and transactions are meant to propagate to everyone. Arguably, this makes Bitcoin better suited for a gossip-based protocol than Gnutella was.
These problems are compounded by Gnutella's flat architecture, which treats every node as equal in the network topology. But when it comes to bandwidth, nodes are not all equal—some nodes stay online more consistently and have more bandwidth to offer. A system becomes instantly more performant if it routes around flakey nodes and self-organizes around the high-reliability ones.
Later file sharing clients like KaZaA or eMule would use more hierarchical topologies with smarter routing. In these systems, well-behaved nodes eventually graduate to "supernode" status, taking on more load in the system. This greatly improved their overall performance relative to flat architectures like Gnutella.
In the next lesson, we'll look at how gossip actually functions in Bitcoin itself, and we'll also dig into the role of privacy in its networking layer.
Assignment
For this assignment, you'll be implementing a simple P2P protocol! This assignment is quite involved, but is a great test of your ability to reason through how P2P protocols work in practice.
Head over to the assignment on repl.it and check out the README.md. Once you read through it, fork the workspace and get to work. There is no test suite for this one; you just have to build out the system until the protocol works.
Once you're finished (and only once you're finished!) you can check your work against the solution, which you can find in a separate branch on the Github repo. Once you're done with this assignment, you'll be ready to move on.
Additional reading
- Gnutella Protocol Specification (SourceForge), Patrick Kirk (2003)
- Napster and Gnutella, and other P2P architectures, from Architecture of Peer-to-Peer Systems, by Quang Hieu Vu, Mihai Lupu, and Beng Chin Ooi (2010)
- Gossip Protocols (video lectures) from University of Illinois Urbana-Champaign's MOOC on Cloud Computing



