
If we want to understand how cryptocurrencies work from the ground up, we'll need more in our toolkit than just cryptography. For a cryptocurrency to work, it needs more than just cryptographic security—it also needs to be decentralized. Satoshi learned a great deal from the history of peer-to-peer (P2P) networking that played out in the early 2000s. Those lessons inform the design of Bitcoin's network layer.
In this module, we'll explore Bitcoin's networking model and how it achieves two of its major goals: decentralization and censorship-resistance.
Networking architectures
Traditional web services are structured in a centralized client-server model. A central server provides a service, and each client requests data or work from this central server. Almost all applications you use on the web are structured this way—Facebook, Google, Wordpress, you name it. Today that "central server" is usually a fleet of servers behind a load balancer, but at a high level, it's fundamentally the same architecture.
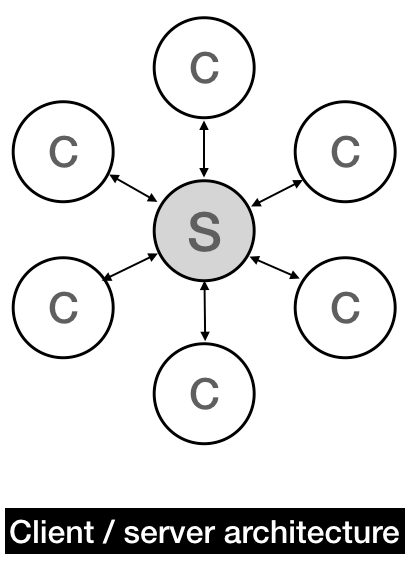
A client/server architecture is fundamentally centralized and dependent on a single party. If the central server shuts down, that service is suspended (as happened to DigiCash).
A P2P network is a distributed model of networking, in which there is no central server. Instead, each peer carries some of the load of the network. This implies that each peer can make queries to the network but also has to respond to queries. You can think of a P2P network like a "swarm" that fuses the roles of client and server.
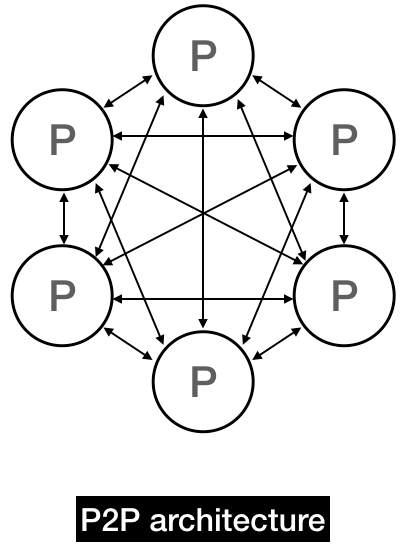
P2P networks are compelling because they allow us to achieve decentralization. A decentralized network is one that depends on no single node, and hence is resilient to any single node shutting down or leaving the network.
So decentralization is cool and all, but brass tacks—how does decentralization actually make a system better?
There are two desirable properties that decentralization gives us: the first property is crash fault-tolerance. Crash fault-tolerance means you're able to withstand individual node faults or failures—even if a single node dies, the system still functions. This is critical to scalability, because large networks have node failures all the time.
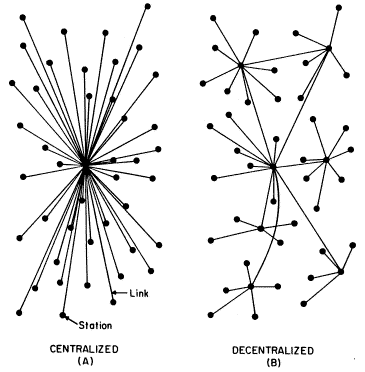
The second property decentralization gives us is censorship resistance. If a single node is censored but the network on the whole is decentralized, then no matter—the rest of the system chugs on. For censorship to be effective, usually every node must collude to enforce the censorship, and that's hard in a large network. If I'm searching for files in a decentralized network, so long as a single node is willing to provide a response to my query, the whole thing still works.
It might not be obvious why we care about either of these properties. After all, who's taking down or censoring these networks? A brief review of the history of P2P protocols will make clear why Satoshi valued these features in Bitcoin.
A brief history of P2P protocols
In the 90s, it was quite rare to coordinate massive computational tasks across large distributed systems. MapReduce or HDFS were yet to be invented, so large-scale distributed computing was rare and expensive. P2P protocols were the first distributed systems that reached massive scale in the number of computers (besides the Internet itself, that is).
Napster was not the first P2P protocol, but it was the first mainstream public success that demonstrated the power of the P2P model.
Napster was founded in 1999 by two college students, Sean Parker and Shawn Fanning. It offered a simple value proposition: it let you download MP3 files from any user in the Napster network.
The architecture of Napster was simple. There was one central Napster service, which was mostly a giant search index that kept track of all the peers and their shared content. It stored content metadata as tuples of: (filename, ip_address, port_number).
Whenever a peer joined the Napster network, the peer would send the central server a list of the files it was willing to share. The server would then update its search index to include those newly shared files.
Whenever a user searched for a file, the server would query its search index and present all relevant hits to the user. Because those hits represented other peers' files, the user would ping the IP of each relevant peer and to determine their download latency and line speed.
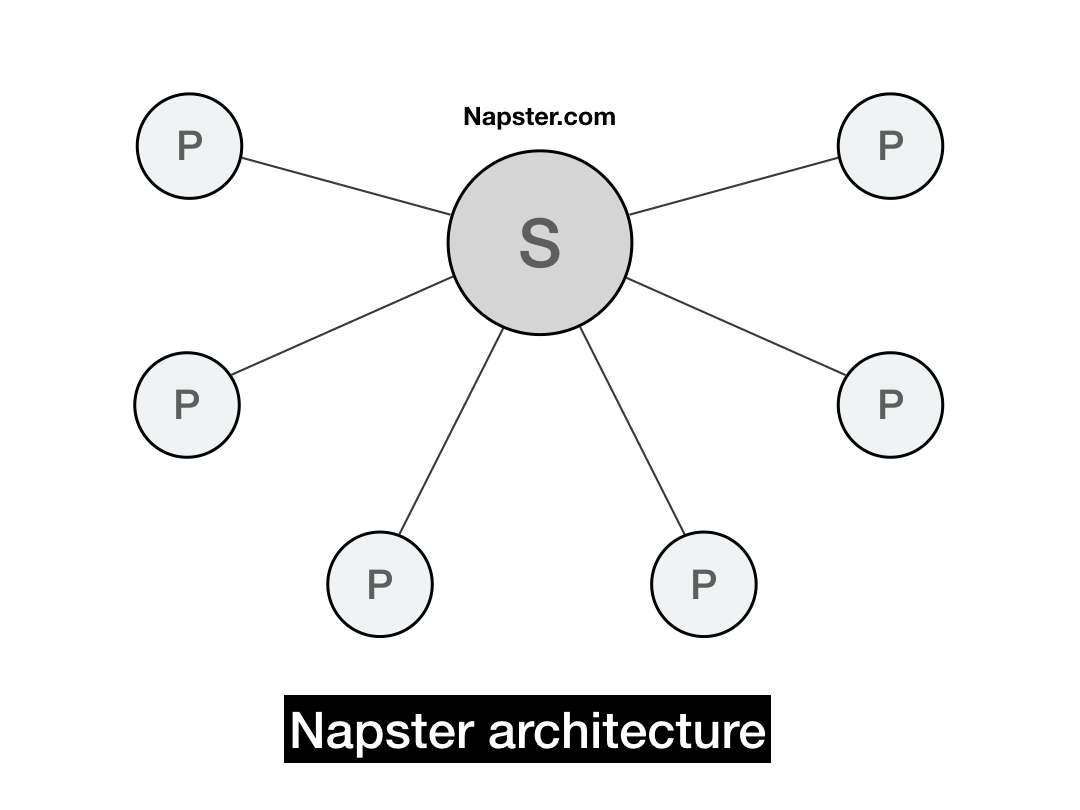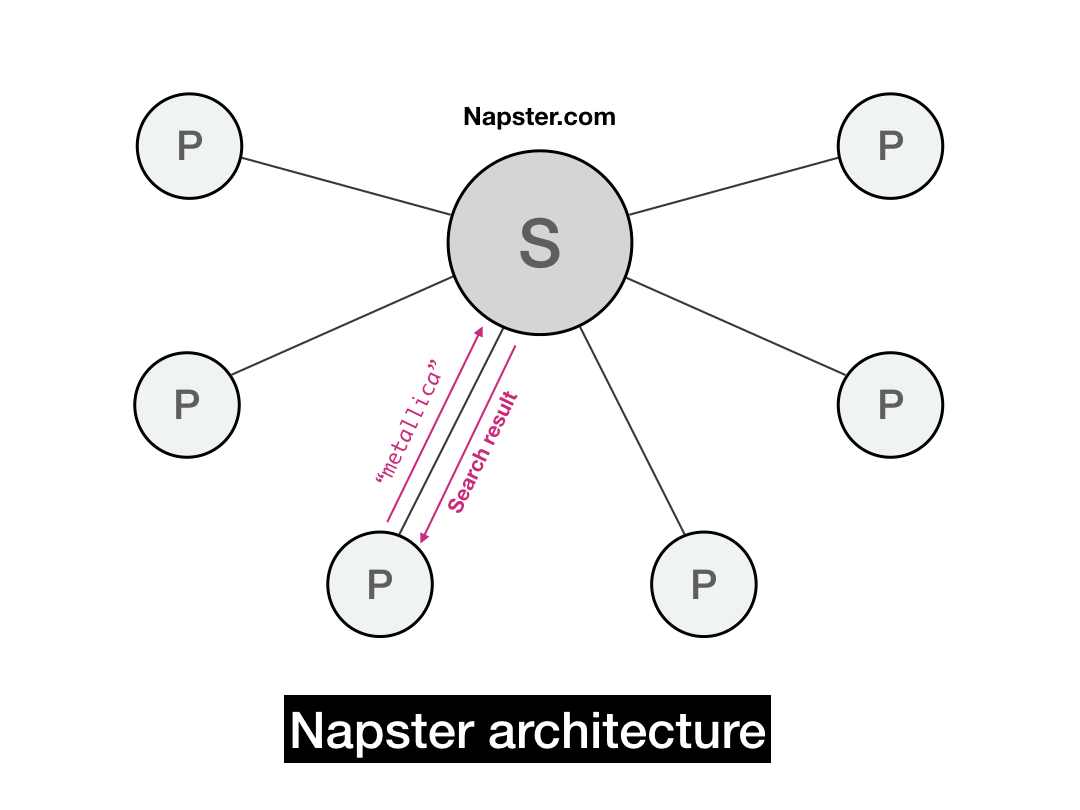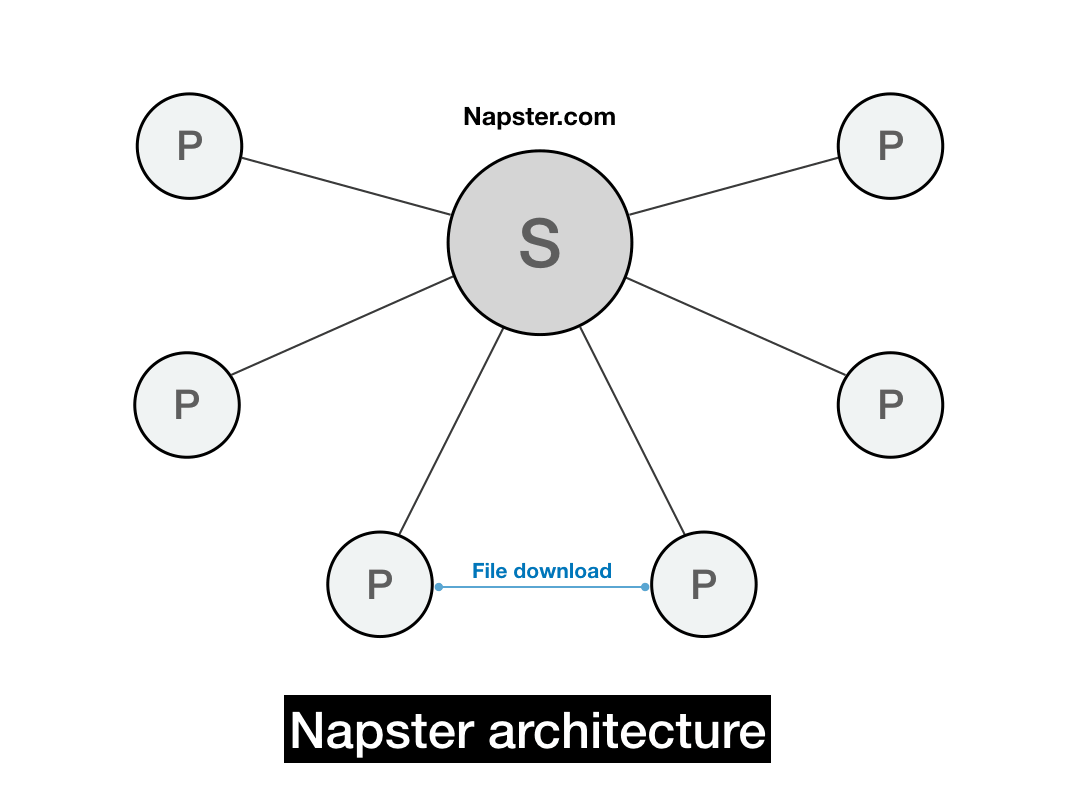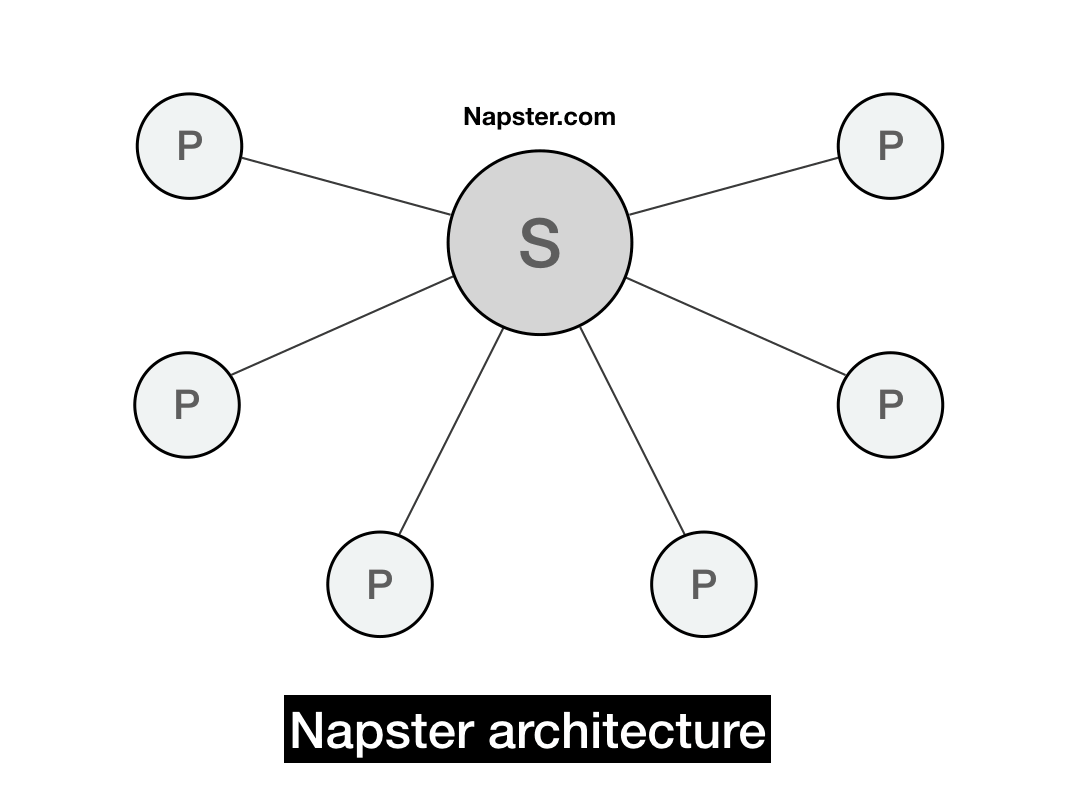
Once a user selected a file to download, their client would fetch the file directly from the IP that corresponded to that file. All file transfers occurred directly between peers. At that point, the Napster server itself was no longer involved.
In a sense, Napster was a cross between a client/server model and a P2P model. The server essentially functioned as a matching engine for MP3 downloaders. And it turned out, there were a whole lot of people who wanted to download MP3s.
Soon after its launch, Napster took off like wildfire. At its peak, the service had over 80 million users. It routinely overloaded high-speed networks in college dorms in 2001 and was quickly banned in many universities.

In 2000, Napster was sued by Metallica, Dr. Dre, and then by A&M records for copyright infringement. These lawsuits succeeded in bringing Napster even more news coverage and publicity. But the show finally came to an end when a judge issued an injunction against Napster to stop the trading of copyrighted music.
The lessons of Napster
Though we call Napster a P2P network, when it came to file discovery, Napster's design was a traditional client-server model. Only file transfers were actually P2P. This gave their architecture a single point of failure and meant the network disappeared after the Napster company shut down.
There was also little consideration for security in Napster. All messages and requests were sent in plaintext and all IPs were public, giving the system little in the way of privacy.
But ultimately, the nail in the coffin for Napster was legal, not technical—Napster was held legally liable for its users' copyright violations. Even though Napster the company did not directly violate any copyrights, a judge ruled that Napster induced their users to violate copyrights, and hence "vicariously infringed" against the copyright holders.
The court demanded that Napster curb all copyright infringement. Napster claimed that it could implement a solution that would stop 99.4% of infringement, but the court deemed that was insufficient unless they could stop 100%.
The Post-Napster World
Napster eventually filed for bankruptcy. Its assets would be purchased and rebranded as Rhapsody. But Napster's burial would kick off a storm so large it that would overshadow its origins. Networks like LimeWire and KaZaA succeeded Napster, establishing more performant and decentralized P2P protocols with fewer limitations than their predecessor.
In time, all of these protocols would eventually be eclipsed by BitTorrent. By 2009, P2P file sharing—mostly BitTorrent—accounted for 70% of all Internet traffic. Fast forwarding to today, BitTorrent is the single largest P2P network in the world, and is the single largest source of upstream traffic in most countries.
It's worth stopping to reflect: why did BitTorrent succeed while most other protocols faded away?
For one, BitTorrent bandwidth sharing works on a tit for tat model, meaning that peers will give more bandwidth to those who are generous to them. This system of reciprocity discourages free riding and encourages paying it forward. (In reality, the tit for tat model doesn't work particularly well, but it's nevertheless an improvement over previous file sharing protocols.) BitTorrent also happens to be very efficient when it comes to bandwidth consumption, especially for files that are in high demand.
But in many ways, the core of BitTorrent's success really came down to their unimpeachable messaging. The developers of the protocol never advocated copyrighted file sharing as a legitimate use of the service. They pitched BitTorrent as "a better way to serve your website," and their website only ever referenced innocuous use cases like Linux distros and downloading World of Warcraft updates.
Even if you wanted to, there was no centralized BitTorrent service to go after. There were only a federated network of privately run BitTorrent trackers. So while other P2P networks were getting shut down by law enforcement, with BitTorrent they could only go after individual trackers. Thanks to BitTorrent's DHT model, many torrents could even survive the takedown of any individual tracker. Thus, censorship attempts against BitTorrent often devolved into a game of whack-a-mole.

The file sharing revolution had deep social consequences on our relationship with technology and media. But its impact did not end there—it also triggered a resurgence of engineering interest in P2P protocols. This led to many academic projects such as Folding@home and SETI@home, where individuals could lend their computing power to world-scale P2P scientific computing projects. There were even successful startups like Skype that were originally built atop P2P architectures.
But as enforcement and legal battles intensified, P2P protocols gradually became synonymous in the public's mind with "illegal file sharing." After enough negative headlines, academic enthusiasm dried up. At the same time, improvements in distributed systems enabled engineers to build larger scale centralized systems, rendering P2P architectures unnecessary for most commercial applications.
Furthermore, it proved difficult to build sustainable business models around P2P protocols. Most content businesses require a central broker or DRM to track usage and collect payments. Almost by definition, a P2P protocol makes it difficult to implement centralized tracking. This was typified by Daniel Ek, the former CEO of uTorrent, abandoning the BitTorrent world to co-found the music company Spotify. All of these factors broadly contributed to the decline of interest in P2P protocols.
This is why by 2009, P2P protocols had largely fallen out of vogue. There were not many new applications that employed large-scale P2P systems outside of file sharing networks.
Nevertheless, Satoshi understood that a P2P architecture was the only viable way to create a resilient, decentralized monetary protocol. Satoshi wrote:
Governments are good at cutting off the heads of a centrally controlled networks like Napster, but pure P2P networks like Gnutella and Tor seem to be holding their own.
What are the tradeoffs of a P2P architecture?
Decentralization doesn't come for free. There are three large handicaps Satoshi had to accept when he chose a P2P architecture for Bitcoin.
The first is this: in centralized architectures, you can often get a single coherent snapshot of the global state (that is, you can clearly observe everything that's happening). But in a P2P protocol, it's usually impossible to get that global snapshot. P2P nodes only store their own local knowledge, and it's quite challenging to stitch together a consistent picture of what's happening in the network.
This is true for example in IP routing. In IP routing, no single router possesses a routing table of the entire Internet. Routers instead pass a packet along to the next closest node they know of, trusting that nodes with more local information will be able to route a packet ever closer toward its destination. Presenting a global snapshot of the activity in the Internet thus proves to be quite challenging.
A second drawback of P2P protocols is that they tend to have high rates of churn as users go online and offline. This means any P2P protocol must be highly fault-tolerant to be usable. Centralized architectures generally don't require anywhere near the same degree of fault tolerance as P2P systems.
But perhaps the largest handicap that P2P protocols face is that they cannot easily enforce quality control. Because P2P membership is usually completely open, any malicious actor is free to join the network and cause a ruckus. In a centralized service, it's straightforward to block such bad actors. But in a decentralized P2P network, who decides who's bad and who's good? A poorly designed moderation function might let bad actors block good users. This means any P2P network must be carefully engineered so that even in the presence of malicious users, the network cannot be subverted.
Despite these tradeoffs, it was clear to Satoshi Nakamoto that the properties of P2P networks were necessary for a decentralized currency.
This concludes our overview of the history of P2P protocols. In the next section, we'll do a deep dive into a famous yet simple P2P protocol, Gnutella. Gnutella will provide us a blueprint for a gossip protocol that will ultimately help us wrap our heads around Bitcoin's own networking model.
Assignment
Take the quiz to test your learning. Once you've completed it, it's time to move on.
Additional resources
- What Does Decentralization Really Mean? Vitalik Buterin (2017)
- Resistant Protocols: How Decentralization Evolves on the history of decentralization in P2P filesharing networks, by John Backus (2018)



